« 本次活动通知: 腾讯+句子互动=碰撞思想,点燃科技 «
Bot Friday Zero - 沙龙第0场分享
关于对话系统/产品/技术
2019-07-19 于北京腾讯,QHDuan
对话系统与Rasa
首先笔者认为: 所谓对话系统,是通过对话的方式,实现人机交互的一种方法
就如同键盘鼠标是输入设备,显示器音箱是输出设备,输入输出是什么?是与计算机交互。对话系统也如此而已。
Rasa是一家通过机器学习技术实现对话系统、机器人开发的工具,同时也是一家创业公司。
Rasa最新于2019年初A轮融资$13M。
笔者认为Rasa最大的创新,是开发了整套的基于机器学习的对话工具,而相对的,如wit.ai,dialogflow(原api.ai),luis.ai等都不够完整。
相对来说国内的unit,yige ai,更完整,但是无论是体验、效果、社区等等都不如rasa。
个人认为:程序员更爱工具,而不是平台。
Rasa的组成
Rasa NLU
主要实现自然语言理解(即NLU)功能,本质上就是识别句子的意图和实体。
如“买一张去北京的票”,我们可以定义一个意图是“购票”,实体是“北京”和“一张”。
意图识别本质是短文本分类任务(当然在学术界可能称为Intent Detection来和Text Classification分开)。 单纯短文本分类任务的SOTA基本上就是BERT了。
抽取本质是信息抽取任务。 抽取的SOTA现在一般还是BiLSTM-CRF的各种变型,或BERT之类。
现在学术界的主要研究方向是多种工作结合,例如同一模型同时做意图识别和信息抽取,互相配合增加总体准确率。
Rasa的NLU,主要是当前的社区版,主要还是使用了各种开源技术,并没有追求学术上的SOTA。 它使用的工具包括Spacy、sklearn-crfsuite
Rasa Core
笔者认为这是Rasa的核心部分,NLU有各种实现,开源的也有snips nlu等,但是core却独一无二。
Rasa Core主要完成了基于故事的对话管理,包括解析故事并生成对话系统中的对话管理模型(Dialog Management),输出系统决策(System Action/System Policy)。
学术上一般认为这部分会包含两个模型
- 对话状态跟踪(Dialog State Tracking / Belief Tracking)
- 对话策略(Dialog Policy / Policy Optimization)
对于1.其实Rasa实现很简单,具体在它的论文 Few-Shot Generalization Across Dialogue Tasks, Vlasov et at., 2018 中说的比较具体。就是简单的基于策略的槽状态替换。
对于2.Rasa使用基于LSTM的Learn to Rank方法,大体上是将当前轮用户意图、上一轮系统行为、当前槽值状态向量化,然后与所有系统行为做相似度学习,以此决定当前轮次的一个或多个系统行为
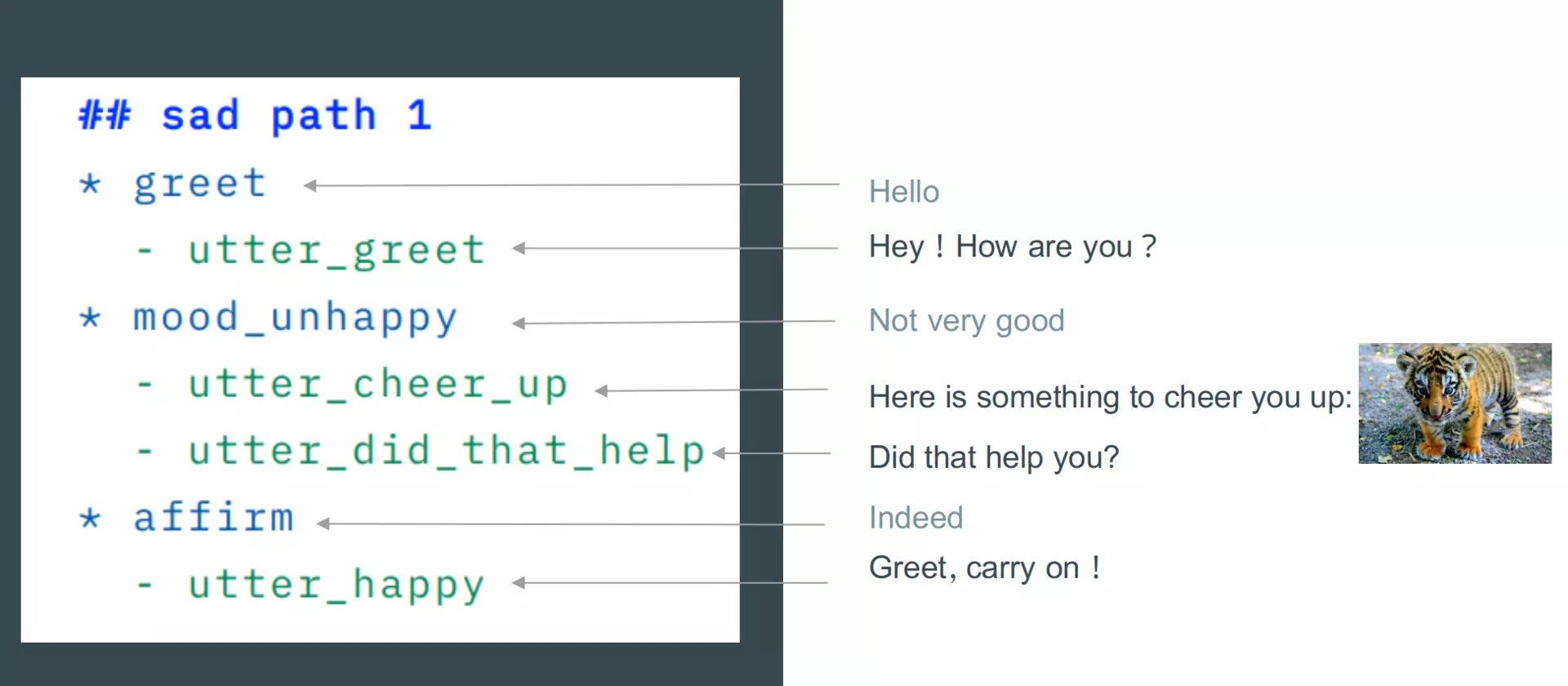
Rasa X
Rasa的可视化编辑工具,更方便NLU、NLG数据的管理,故事的编写。
Rasa X可能暂时还不能让所有非开发人员也能快速方便的使用。不过它本质上可以方便开发人员快速开发,快速训练模型验证。
笔者是这么认为的,Rasa X就好像小程序开发也要有个本地开发工具一样,或者像Android Studio那样的工具。本地工具的优点就是方便调试、开发、快速验证、Debug。相对线上的缺点就是速度慢、验证需要等待后台训练、不便于Debug。
可以看出国内外现在很多机器人平台都是完全在线的,例如国外的luis.ai,dialogflow等。这样当然也可以,但是总还是不如有一个可自己训练的终端对开发者更友好。 国内的就不说了。
再举个例子,如Elasticsearch、Docker都是非常棒的工具,但是如果官方开始的时候说:你不能自己本地架设,你只能用我的云服务。这样对于很多开发者来说就必然丧失了很大的兴趣。
Rasa 的 Pipeline
Pipeline 的过程是这样的:
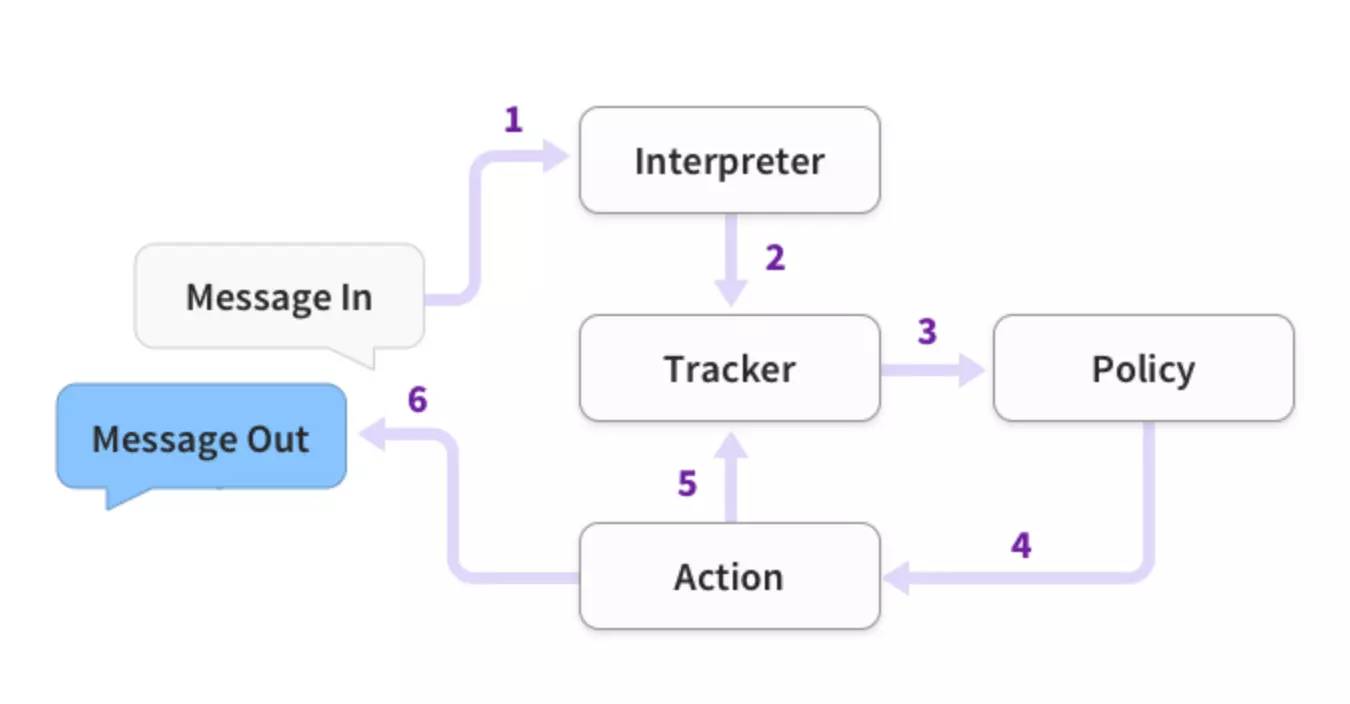
- 用户输入文字,送入解释器,即Rasa NLU
- NLU给出结果,如图

- 从Tracker到Policy,Tracker用于跟踪对话状态,Tracker输出的是Embedding
- 用户意图的Embedding
- 系统动作(上一步)的Embedding
- 实体(槽值/Slot)的Embedding
- Policy给出系统行为
- Tracker记录系统行为,下一次会提供给Policy使用
- 返回消息给用户
Rasa技术详细
Embedding 方法
用户意图和系统行为会通过bag-of-word的方法分词,然后向量化,很有趣的结果。在官方论文没有仔细探讨为什么,笔者猜测是为了增加不同的意图、行为之间的语义关联。
论文原文:
A bag-of-words representations for the user and the system labels are then created using token counts inside each label.
例如:
action_search_restaurant = {action, search, restaurant}
实体/槽值(Slot)的向量化就非常简单了,只是走了是否存在的binary向量
The slots are featurized as binary vectors, indicating their presence or absence at each step of the dialogue.
Learn to Rank 方法
很多对话系统的系统决策都采用的是分类(Classification)方法,也就是每次总是在多个系统行为中选择唯一一个。
而Rasa选择了排序方法,即判断当前对话状态和系统行为的相似度,笔者认为这有两个可能的好处(论文没说明):
- 可以更容易实现多个系统行为的同时输出。能让一个对话状态输出多个系统行为是Rasa的特色。至于为什么如此,可能有工程上的一些考虑,例如这样更方便,例如两个系统行为,一个是机器人说“请等待”,一个是真的去查询数据。
- 更方便扩展系统行为。如果是分类模型,增加一个分类,那必须重新训练整个分类器。如果是Ranking模型,如果只是增加或减少分类,可以考虑只训练新增的系统行为相关的和不相关的部分数据集,可能增加总体的训练速度。更方便快速实验、迭代。
总结
优点
- 机器学习方法的好处是实际工程上代码量比较少,很多状态不需要写判断(对比专家系统)
- 可以做到不写逻辑下,快速验证某些场景或对话流。例如一个非开发者甚至可以不需要写一行代码就能搭建某种原型机器人。
缺点
- 要做好一个比较复杂的机器人,还是需要对机器学习有了解的工程师
- 针对复杂的机器人,可能需要大量数据
