![]()
![]()
微信机器人
微信机器人是很常见的运营工具,不仅能够给微信群带来活跃度,还能针对各种社群开发不同的玩法。
我想要做的是一个诗歌机器人,当群内有人@机器人或者用搜索词触发时,机器人从已有的诗歌数据库中查询一首相关的诗歌,以文字形式回复在群内。
有了这个目标以后,我开始了漫长的折腾。
之所以说是折腾,是因为这一路真是障碍重重。
首先,微信官方并没有相关的 API。可能要考虑考虑企业微信?结果发现企业微信有群机器人,但只支持发送信息,不支持接收。还是得找微信个人号 API。
然后我看了看基于 Web 版微信的各种开源方案,最近一次更新基本是几年前的,issue 列表里常常看见登录不了 Web 版微信的问题。我试了试自己开发用的微信小号,登不了 Web 版微信,放弃。
再然后我试用了基于 PC 版微信的 Mocha-L/WechatPCAPI。虽然能用,但是有不少问题。比如获取不了昵称带 emoji 的用户的消息,每次修改完代码必须手动重新启动微信。我相信这些都是可以解决的,但是开发者并没有完全开源核心代码,无从下手。项目主页上写的是有免费版和收费版,我只成功运行了收费版,十几天后,提示试用到期了。这个基于非常规的 HOOK 的方案只能用指定版本的 PC 版微信,需要 Windows 运行环境。考虑到我需要的是一个较长期稳定运行的 API,且能在 Linux 服务器上使用,而且收发信息相对安全,我只能继续寻找更好的方案。
折腾到这里,我已经对各类方案有了基本了解:主要有 Web 网页端、Xpsoed 技术、PC Hook、iPad 协议、模拟机、MAC 协议这六类方案,从稳定性和安全性上比较,iPad 协议和 Mac 协议的方案是比较好的,商业上的应用也比较多。
此时我找到了 beclass 的博文 《基于Nodejs+Wechaty开发微信机器人管理平台》。发现了 Wechaty 这个项目,支持 iPad 协议,虽然需要付费获取 token,但是可以申请参与开源激励计划来获取免费甚至长期有效的 token。
具体实现
基本构架
由于前期尝试各种个人号 API 的方案,已经把搜索诗歌的部分独立出来作为一个服务。这个搜素服务接受查询字符串,返回一个包含结果的 json 字符串。
至于跟微信相关的部分,就全部交给 Wechaty 了,包括接收微信消息,查询到诗歌内容以后发送微信消息。
诗歌搜索服务
此部分用 PHP+MySQL 实现。诗歌数据库是从某诗歌博客数据库导入,并且用爬虫抓取相关微信公众号文章信息(机器人可以发送公众号文章链接)。
此部分的难点在于博客数据库的诗歌并没有区分标题、内容、诗作者等字段,需要用正则表达式匹配出各个字段内容。虽然大部分的诗歌是有固定格式的,可以通过特定的 html 标签确定标题、诗作者在整个字符串的位置,但不同时期添加进数据库的诗歌格式有细微的区别。
一开始,我试图用一个正则表达式描述尽可能多的格式类型,并且在其中描述所有字段的位置。在折腾了一阵以后我放弃了。
由于对正则表达式具体运行机制不熟悉,它在我眼里就是那种一看就懂,一写就错的外星语言。我需要一个工具来展现正则表达式如何一步步匹配目标字符串,加速我的正则调试过程。
Windows 平台下,我用过 RegexBuddy。我发现了一个更好的 Web 平台正则调试工具 regex101。它不仅能清楚标注匹配结果,还能展现正则一步步匹配的过程,这对于调试来说至关重要。
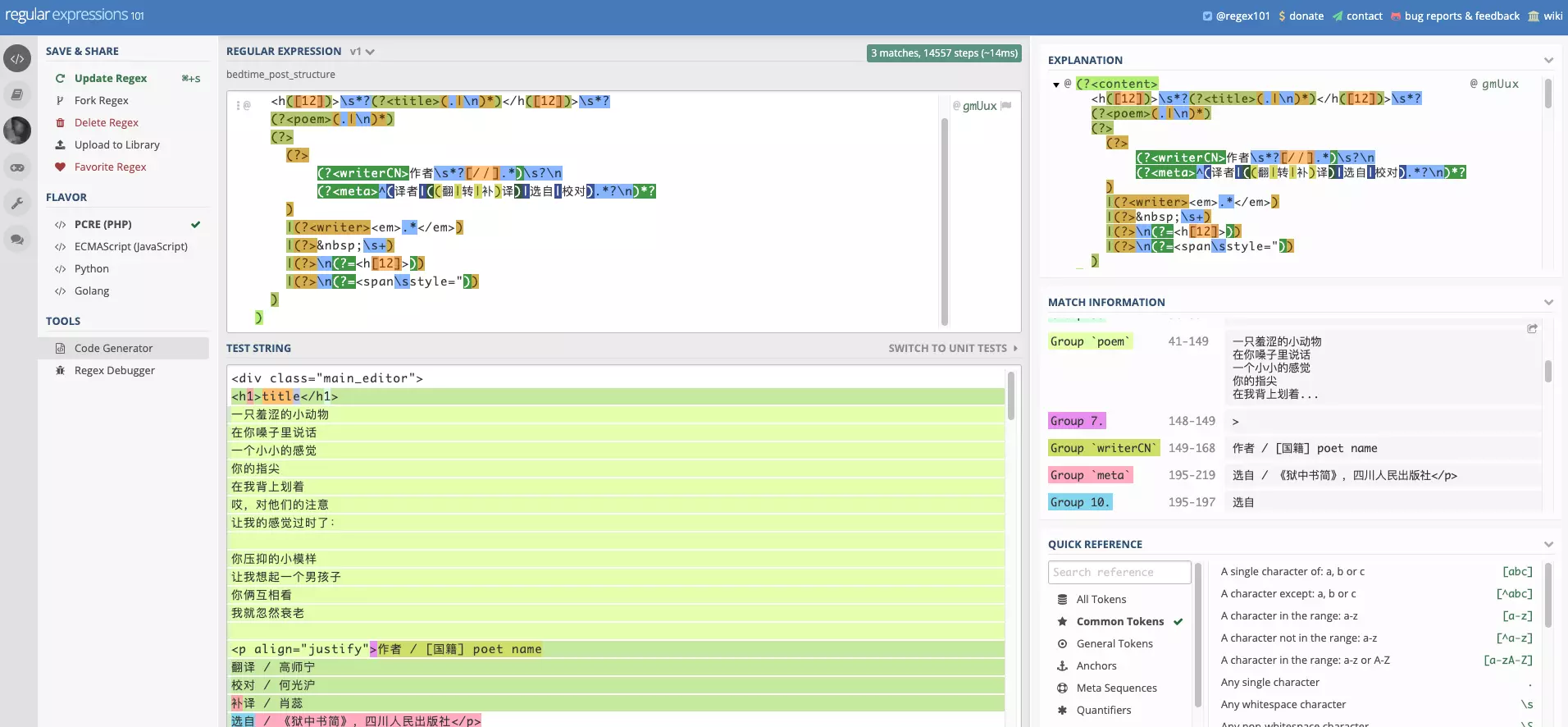
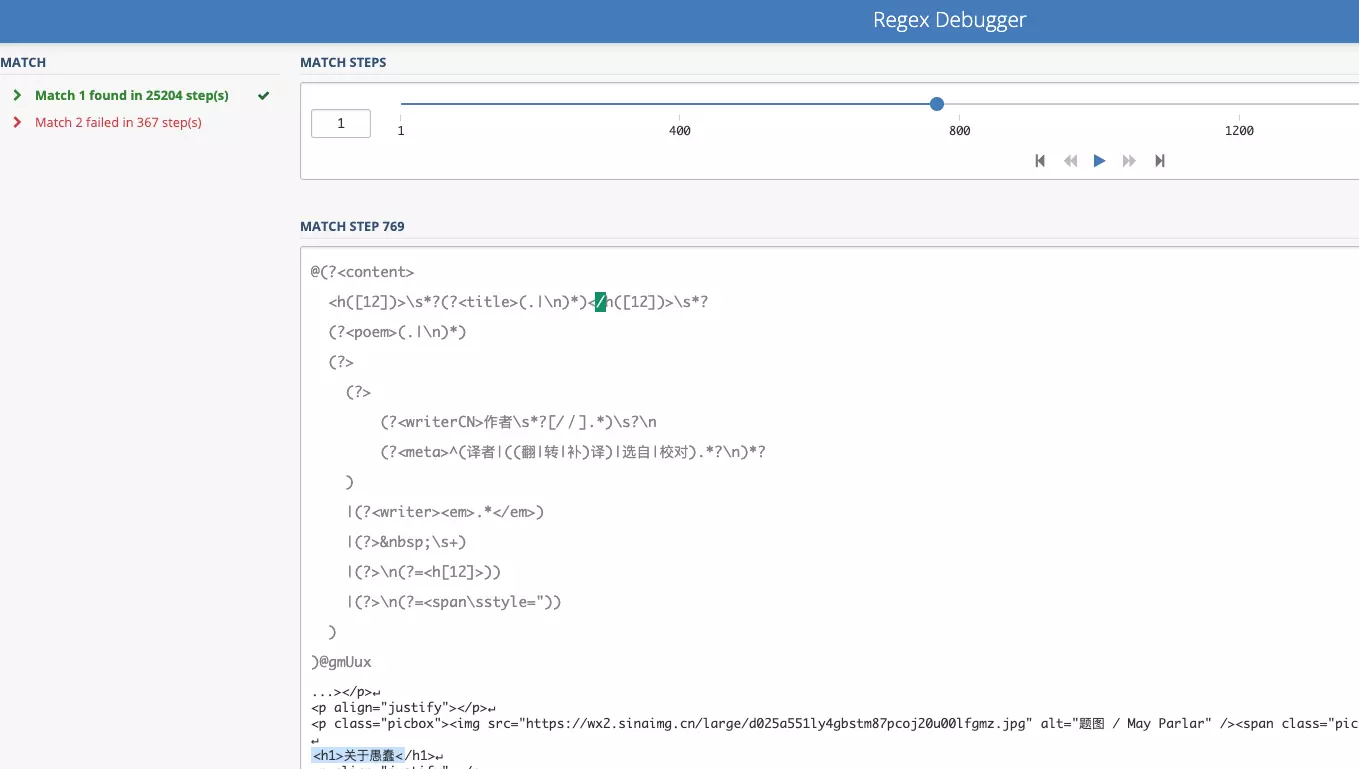
除了用正则提取诗歌各字段,还需要匹配各种可能句式中的关键词。测试用例如下:
public function testGetKeywordStartWithSearch() {
$this->assertEquals('', getKeyword('搜索'));
$this->assertEquals('诗', getKeyword('搜诗'));
$this->assertEquals('小黄诗', getKeyword('搜小黄诗'));
$this->assertEquals('一下', getKeyword('搜索 一下'));
$this->assertEquals('一下', getKeyword('搜 一下'));
$this->assertEquals('大人', getKeyword('搜大人'));
$this->assertEquals('你大爷', getKeyword('搜你大爷'));
$this->assertEquals('大人', getKeyword('搜一下大人的诗?'));
$this->assertEquals('李白', getKeyword('搜一搜李白的诗歌'));
$this->assertEquals('李白', getKeyword('搜一搜李白的诗.'));
$this->assertEquals('李白', getKeyword('搜一搜李白的诗。'));
$this->assertEquals('李白', getKeyword('搜一首李白的诗。'));
$this->assertEquals('李白', getKeyword('搜一首李白。'));
$this->assertEquals('李白', getKeyword('搜一搜李白的现代诗。'));
$this->assertEquals('唐', getKeyword('搜唐诗。'));
$this->assertEquals('宋', getKeyword('搜 宋词。'));
$this->assertEquals('搜索', getKeyword('搜索一下搜索'));
$this->assertEquals('dd索', getKeyword('搜索一下dd索'));
$this->assertEquals('搜索', getKeyword('搜搜索'));
$this->assertEquals('搜索', getKeyword('搜 搜索'));
$this->assertEquals('搜索', getKeyword('搜索 搜索'));
$this->assertEquals('你大姐', getKeyword('搜索:你大姐'));
$this->assertEquals('你大姐', getKeyword('搜索:你大姐'));
$this->assertEquals('text', getKeyword('search text'));
}
public function testGetKeywordStartWithOther() {
$this->assertEquals('', getKeyword('帮我找'));
$this->assertEquals('辛弃疾拍栏杆', getKeyword('我想要辛弃疾拍栏杆的诗'));
$this->assertEquals(['辛弃疾', '拍', '栏杆'], getKeyword('我想要辛弃疾拍栏杆的诗', true));
$this->assertEquals('一下', getKeyword('来一首 一下的诗'));
$this->assertEquals('杜牧', getKeyword('给我来一个杜牧的诗'));
$this->assertEquals('李商隐', getKeyword('给我来一个 李商隐的诗'));
$this->assertEquals('杜甫', getKeyword('给我一个杜甫的诗'));
$this->assertEquals('杜牧', getKeyword('告诉我一首杜牧的诗'));
$this->assertEquals('海子写德令哈', getKeyword('我想要那个海子写德令哈的诗'));
$this->assertEquals('海子写半截', getKeyword('我想要哪个海子写半截的诗'));
$this->assertEquals('写诗', getKeyword('帮我找跟写诗有关的诗'));
$this->assertEquals('写诗', getKeyword('帮我找一首写诗的诗'));
$this->assertEquals('李白', getKeyword('有没有李白的诗歌'));
$this->assertEquals('李白', getKeyword('有没有李白的古诗'));
$this->assertEquals('杜甫', getKeyword('来一首杜甫的诗'));
$this->assertEquals('海子', getKeyword('有没有海子的现代诗'));
$this->assertEquals(['李白的', '现代'], getKeyword('有没有李白的 现代 诗'));
$this->assertEquals('天空', getKeyword('来一个带天空的诗'));
$this->assertEquals('天空', getKeyword('来一个带有天空的诗'));
$this->assertEquals('天空', getKeyword('来一个含"天空"的诗'));
$this->assertEquals('天空', getKeyword('来一个包含天空的诗'));
$this->assertEquals('天空', getKeyword('来一个含有天空的诗'));
$this->assertEquals('莎士比亚', getKeyword('有没有莎士比亚的十四行诗'));
$this->assertEquals('天空', getKeyword('有没有跟天空相关的诗'));
$this->assertEquals('天空', getKeyword('有没有和天空有关的诗'));
$this->assertEquals('唐', getKeyword('来一首唐诗'));
$this->assertEquals('宋', getKeyword('给我来一个宋词'));
$this->assertEquals('宋', getKeyword('给我来个宋词'));
$this->assertEquals('天空', getKeyword('有没有跟天空相关的诗歌'));
$this->assertEquals('', getKeyword('一首没有人的诗'));
$this->assertEquals('', getKeyword('那个写火车的诗'));
$this->assertEquals('', getKeyword('帮我找'));
$this->assertEquals('', getKeyword('有没人'));
$this->assertEquals('', getKeyword('有没有人'));
$this->assertEquals('', getKeyword('有没有谁能告诉我'));
}
这个部分也花了不少时间,最终写出来的获取关键词的方法如下:
/**
* @param string $str
* @param boolean $divide
* @return string[]|string
*/
function getKeyword($str, $divide = false) {
$str = trim(preg_replace('@[[:punct:]\n\r~| \s]+@u', ' ', $str));
$keyword = '';
$matches = [];
preg_match('@^(搜索??|search)(一下|一搜|一首|一个)??\s*?(?<keyword>.*)(的?((古|现代)?诗歌?|词))?$@Uu', $str, $matches);
if(isset($matches['keyword'])) {
$keyword = trim($matches['keyword']);
} else {
$matches = [];
preg_match('@^(有没有??|告诉我|帮我找|我想要|(给我来|给我|来)|搜索?)(一首|(一|那|哪)?个|一下)??((和|跟|带|包?含)有??)??\s*?(?<keyword>.*)((有关|相关)?的?((十四行|十六行|古|现代)?诗歌?|词))$@Uu', $str, $matches);
$keyword = isset($matches['keyword']) ? trim($matches['keyword']) : '';
}
// 部分情况下,可能需要返回分词结果
if($divide) {
return Jieba::cut($keyword);
}
return strstr($keyword, ' ')
? explode(' ', $keyword)
: $keyword;
}
中文分词的部分使用了 jieba-php,效率不是很高,内存占用比较大,但是可以接受。
使用 Wechaty 收发消息
在 Wechaty 中,不同的 Puppet 对应不同的协议。Wechaty 还有不同语言的 SDK,以及 demo template repository,对开发者非常友好,开发者参与度也很高。
感谢 beclass 已经开源了一个成功的案例,我不必从头开始,而是在 beclass/wxbot 的基础上改动少量代码。
beclass 的文章 已经介绍了 wxbot 项目,下面不再详细解析 wxbot 的代码,只抽取关键部分。
首先需要初始化一个 bot:
// create a Wechaty instance as bot
let bot = new Wechaty({
puppet: new PuppetPadplus({
token: puppet_padplus_token
}),
name: 'poem'
})
由于申请的是 iPad 协议的 token,这里用到的是 PuppetPadplus。
接着对 bot 绑定各种事件的处理函数,其中 message 事件是接收到消息时触发的事件。
bot.on('scan', (qrcode) => {
// show the qrcode
}).on('login', onLogin)
.on('message', onMessage(bot))
.on('friendship', onFriendShip)
.on('room-join', onRoomJoin)
.on('room-leave', onRoomLeave)
.on('error', error => {
logger.error('机器故障,error:' + error)
})
.on('logout', onLogout)
onMessage 是写在 server/roobt/message 里的
async function onMessage(msg) {
// 忽略来自自己的消息
if (msg.self()) return
// 目前只处理来自群聊的文本消息
if (msg.type() == Message.Type.Text) {
const room = msg.room()
const text = msg.text()
// 消息来自群聊
if (room) {
if (await msg.mentionSelf()) { //@了机器人
let self = await msg.to()
self = "@" + self.name()
let receivedText = text.replace(self, "").trim()
let content = await getPoemReply(receivedText, room.id)
// 返回消息,并@来自人
if(content.poem) {
let poem = "\n\n" + content.poem
room.say(poem, msg.from())
if(!content.data.wxPost) {
return;
}
const linkPayload = new UrlLink({
description : '点击查看读睡荐诗',
thumbnailUrl: content.data.wxPost.cover_src,
title : content.data.wxPost.title,
url : content.data.wxPost.link,
})
room.say(linkPayload)
}
return
} else { // 没有@机器人
const receivedText = text.trim()
// 只处理包含关键词的消息
if(!isSearchString(receivedText)) {
return;
}
const content = await getPoemReply(receivedText, room.id)
if(content) room.say(content.poem)
return
}
}
return
}
}
function isSearchString(text) {
return /^搜/.test(text) || /的诗歌?$/.test(text)
}
/**
* @description 回复内容
* @param {String} info 收到消息
* @return {Promise} 响应内容
*/
async function getPoemReply(word, chatRoomId) {
let url = POEMAPI_HOST + '/bot_search.php'
const pkg = {
method: 'get',
headers: {
'Content-Type': 'application/json'
},
data: {
keyword: word,
chatroom: chatRoomId
},
encoding: null,
timeout: 5000,
}
let { status, data } = await urllib.request(url, pkg)
if (status !== 200) return '不好意思,我出故障了.'
data = JSON.parse(data.toString())
return data
}
上线
在 production 环境运行,建议使用 PM2 。
使用起来也很简单,新增一个配置文件 pm2.config.js
module.exports = {
apps: [{
name: "wx-robot",
script: "./server/index.js",
env: {
NODE_ENV: "production",
}
}]
}
然后命令行执行 pm2 start pm2.config.js。
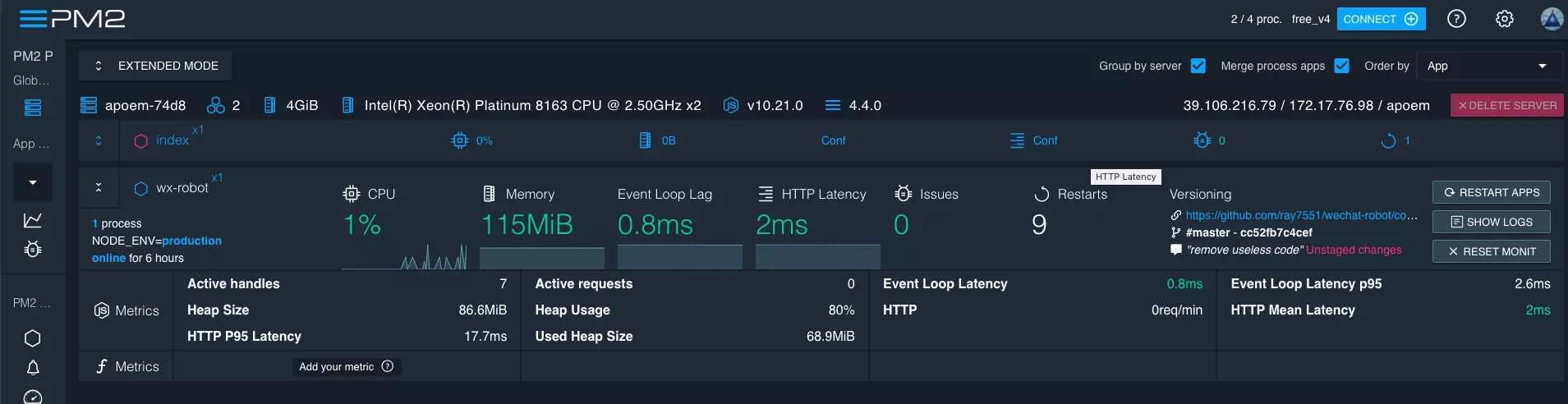
搭配其监控面板服务 PM2+,不仅可以在浏览器中控制任务运行状态,还能查看实时日志:
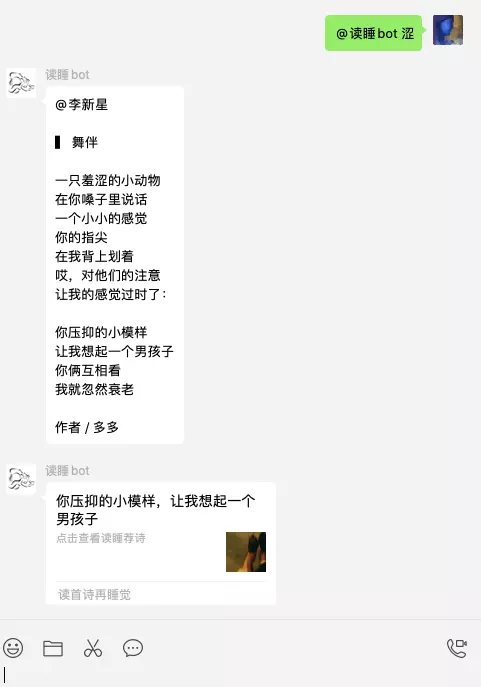
目标达成:
结论(以及广告)
开发阶段我认为比较重要的部分,匹配各种搜索句式中的关键词,花费了很多时间,甚至还想过用 NL2SQL(自然语言转换为SQL) 技术来做。其实在上线以后很少有人用到,大部分人还是习惯于用 搜+关键词 的方式触发机器人搜索。虽然做的过程很开心,但是没有人用还是挺心酸的。
还可以改进或拓展的地方:
- 用 ElasticSearch 代替 MySQL 的搜索,对诗歌内容进行分词(对于诗歌内容,分词结果做到正确很难),让搜索结果更准确。
- 对不同的群,分别设置机器人的功能开关。
- 每次的搜索结果应该尽可能不一样。
- 名句对答模式:如果有消息被判定为名句,机器人接下一句。
- 飞花令模式:诗句接龙。
- 被拍一拍时反拍一下。
微信机器人这样常见的需求就应该有简单的做法。在排除各种不靠谱方案以后,我选择了 Wechaty。 Wechaty 简洁的 API 可以帮助开发者快速地搭建一个微信个人号机器人。没有时间折腾的开发者,就不用花时间尝试其它方案了。
One More Thing
在此文写作过程中,我一直在想,什么样的技术博文才是好的?讲述各种细节固然是对其它开发者有用的。但软件是一直在变化的,这些有用的细节过不了多久可能就不适用了,反而成为开发者搜索过程中的信息噪音。
Redis 开发者 Salvatore Sanfilippo 在这篇文章中说
Sometimes I believe that software, while great, will never be huge like writing a book that will survive for centuries. Note because it is not as great per-se, but because as a side effect it is also useful… and will be replaced when something more useful is around.
在我看来,好的技术博文不应只有细节,还要有对细节的思考,对开发过程本身的观察,试图提炼出让开发过程更顺畅的经验。这些经验,甚至可以拓展到其它日常事务的处理过程中去。
互联网每天产生和复制那么多技术博文,能有多少是可以在多年之后仍然给人启发的呢?
作者: ray7551
This post is also available in English version.
 Implementing a WeChat Poetry Search Robot with Wechaty (wechat poem robot)
Implementing a WeChat Poetry Search Robot with Wechaty (wechat poem robot)