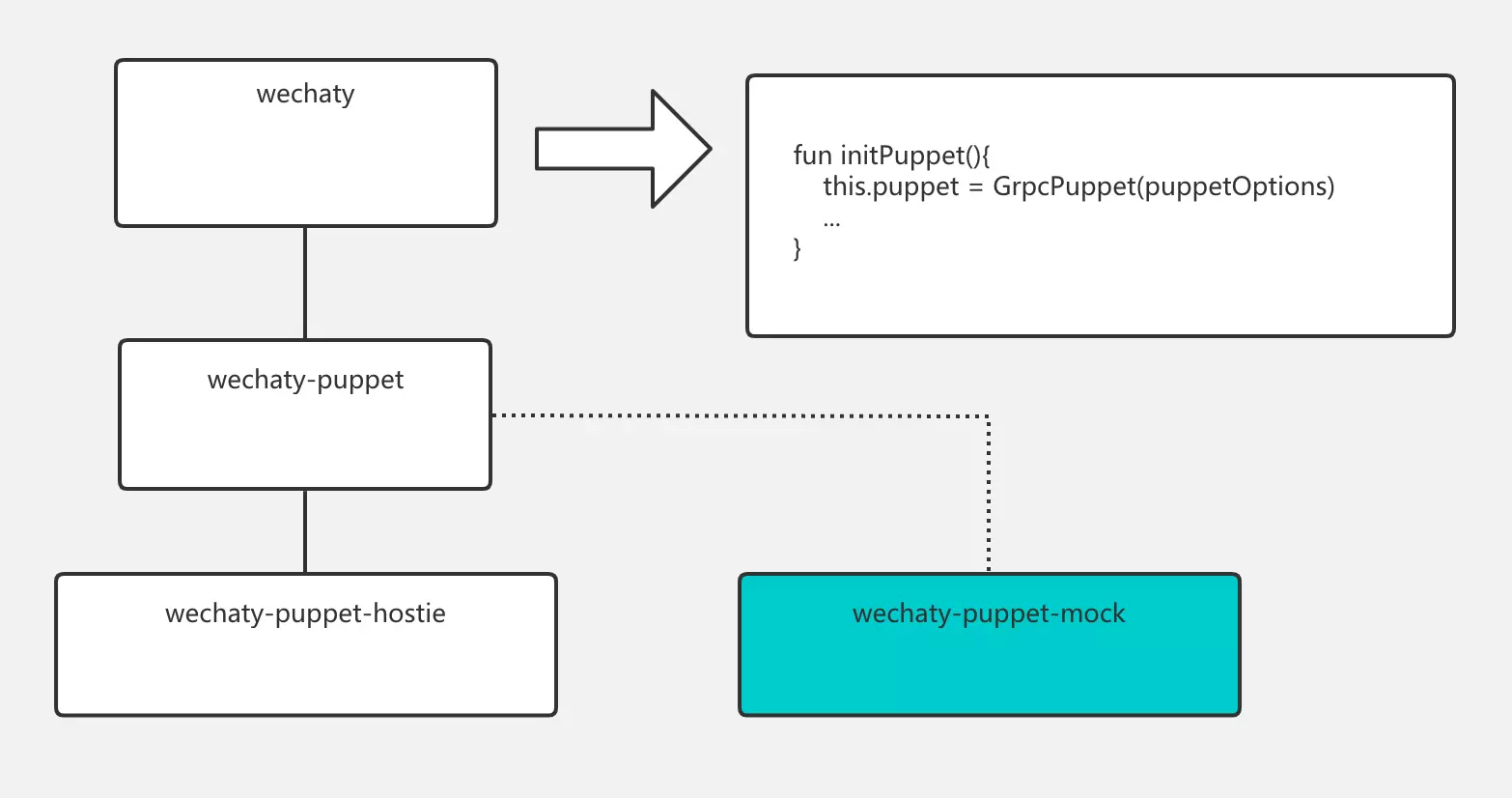
“开源软件供应链点亮计划-暑期2020”(以下简称 暑期2020)是由中科院软件所与 openEuler 社区共同举办的一项面向高校学生的暑期活动。 旨在鼓励在校学生积极参与开源软件的开发维护,促进国内优秀开源软件社区的蓬勃发展。 根据项目的难易程度和完成情况,参与者还可获取“开源软件供应链点亮计划-暑期2020”活动奖金和奖杯。 官网:https://isrc.iscas.ac.cn/summer2020 官方新闻:http://www.iscas.ac.cn/xshd2016/xshy2016/202004/t20200426_5563484.html 本项目 基于Python-wechaty建立一个斗图机器人 系 暑期2020 支持的开源项目。
[基于Python-wechaty建立一个斗图机器人]结项报告
-
导师:黄纯洪
-
学生:肖子霖
-
项目名称:基于Python-wechaty建立一个斗图机器人
-
方案描述:在导师的指导下,我利用OCR、NLP分词与对话系统等相关技术,实现了以下功能:
-
提取用户所发送表情包的内容;
-
将提取内容送入GPT2对话模型,并根据对话系统输出判断下一步回应:利用互相关Loss在候选回答中按互相关Loss升序排序选出最符合语义的回答,如果回答能匹配数据库中已有表情则回复对应表情,否则直接使用提取内容匹配数据库内容;具体技术方案泳道图见下:
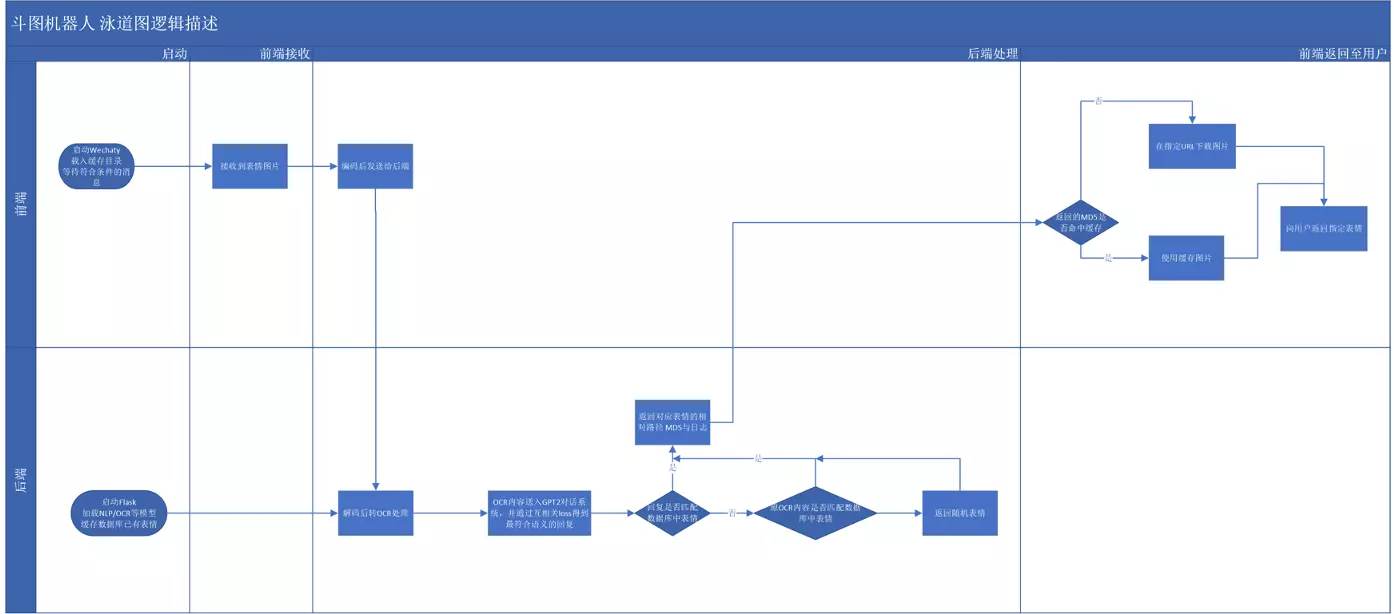
更多细节可参见项目README.
-
-
时间规划(摘自项目申请书):
- Week1:仔细阅读python-wechaty项目源码,掌握项目大体框架和可用API;
- Week2:收集表情包数据,选择合适的网络模型。
- Week3~Week4:训练模型,调试参数;
- Week5:开发核心模块,编写单元测试;
- Week6:开发、配置表情包后端;
- Week7~Week8:模块联调,编写测试样例,上线测试。
项目总结
-
项目成果: 在本次暑期2020活动中,我向Wechaty社区贡献了已完成以下工作的wechaty-meme-bot项目:
- 基于peewee搭建的表情包管理数据库;
- 基于BeautifulSoup搭建的、可扩展的表情包爬取、收集、导入模块;
- 针对表情包的OCR提取模块;
- 针对表情包的Inception特征提取模型,Deep Cosine Metric Learning for Person Re-identification一文中有关Metric Learning部分的相关训练、验证、测试模块;
- 基于python-wechaty的前端回复模块;
- 基于Flask-restful的后端表情包回复接口;
- 基于GPT2对话模型的回复生成机制;
- 基于Github Actions的斗图机器人CI/CD流程;
- 完整的使用、部署教程;
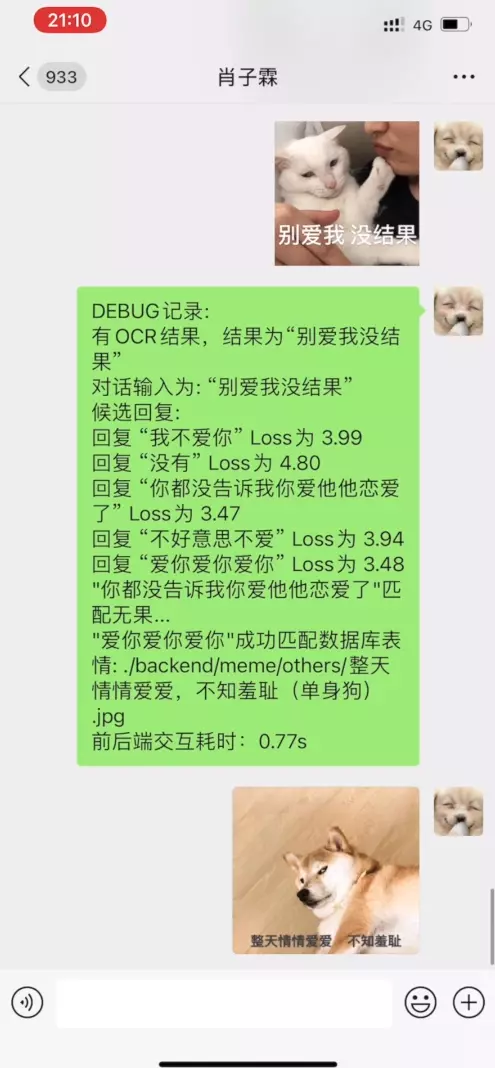
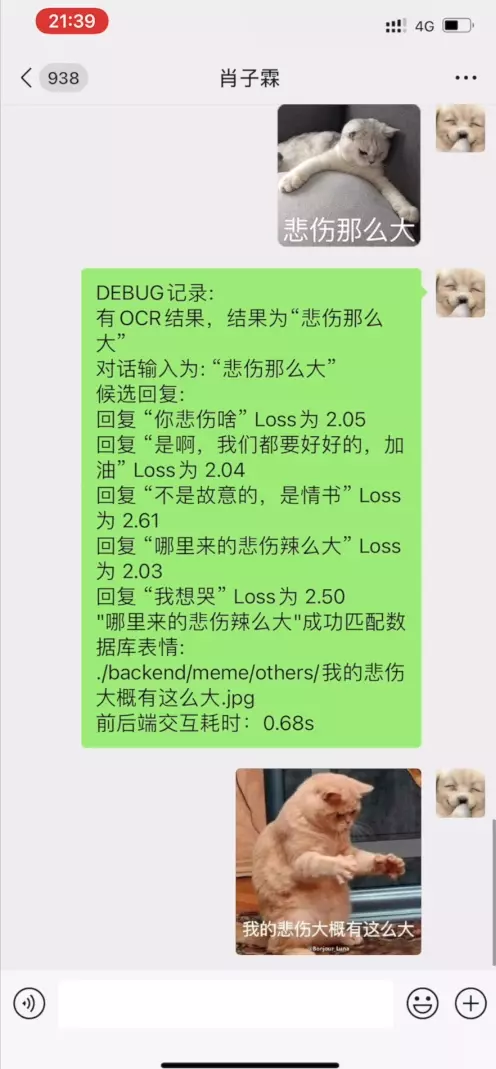
具有代表性的对话参见:
-
遇到的问题及解决方案:
- 前期开发方向与导师原意有所偏差,在与导师充分交流沟通后及时调整了开发方向,由原先的
仅提取内容与特征并进行匹配转变为项目需要体现斗图机器人的对话特性; - 表情收集困难:在本项目中表情包数量直接决定了回复表情的合理程度,如果表情数据库中表情数量过少,即便对话系统输出结果本身很优秀,也无法在数据库中匹配出符合条件的表情;为此,我在Github上搜寻了到了按主题分类的ChineseBQB表情包仓库,同时编写了BaseSpider与爬取
发表情网站的爬虫,若需要爬取其他表情包网站只需继承BaseSpider并覆写download方法即可; - GPT2模型参数量较大,自行收集闲聊语料训练时由于训练硬件条件限制,模型难以收敛;为此,我使用了来自GPT2-chitchat的闲聊语料预训练模型;
- python-wechaty对FileBox的say()间歇性失效导致开发后期调试缓慢(Issue链接),由此原因在DemoLive视频中我将只播放提前剪辑好的测试视频,以免上述情况影响展示效果;
- 前期开发方向与导师原意有所偏差,在与导师充分交流沟通后及时调整了开发方向,由原先的
结项PPT演示 & Demo视频链接
PPT演示:
Bilibili: https://www.bilibili.com/video/BV18f4y1D7GN/
Youtube:
Demo Live视频:
Bilibili: https://www.bilibili.com/video/BV14A411J783/
Youtube:
Reference
Open-Source Reference
- chineseocr_lite: Powerful Chinese OCR module with accurate results and fast inference.
- HaNLP: Multilingual NLP library for researchers and companies, built on TensorFlow 2.0.
- Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
- GPT2-Chinese: Chinese version of GPT2 training code, using BERT tokenizer.
Academic Citation
# in backend/cosine_metric_net.py
[1]N. Wojke and A. Bewley, “Deep Cosine Metric Learning for Person Re-identification,” in 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, Mar. 2018, pp. 748–756, doi: 10.1109/WACV.2018.00087.
# GPT2 Original Paper
[2]Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI Blog 1.8 (2019): 9.
联系我们
- 项目链接:@python-wechaty-meme-bot
- 联系方式:me#mrxiao.net (# -> @)
评审对象
- 评审内容:结项报告
- 提交人:肖子霖
评审结果
- 项目完成度:项目的初衷是做一个“能”斗图以及“会”斗图的机器人,肖子霖在项目中期完成了“能”斗图的机器人,在项目的后期,“能”斗图的机器人也是完成了升华,成为“会”斗图的机器人。从最终结果来看,肖子霖同学的完成情况还是比较好的。
- 学生参与度:在项目后期的实施过程中,肖子霖同学克服各种困难,在自己不熟悉的领域,比如自然语言处理,也是取得了一定的成绩,这一点是可以肯定的。在项目过程中,肖子霖积极参与项目的开发,在未知的领域中进行探索,努力寻找解决问题的方案与办法,最终完成一个”会”斗图的机器人。
- 代码贡献量:本项目在后期的话,由于机器学习的特殊性质,可能代码量并不是特别多,工作量上面主要突出在不断修改模型以及调参,最终一个“会”斗图的机器人才能得以完成。
- 综合评价及建议:总体上来说,本次项目肖子霖同学完成得不错。从一开始的表情包的识别,包括文字识别和情感识别,到后来的“能”斗图的机器人,再到最后的“会”斗图的机器人,肖子霖同学都用实际行动完成了项目。 最后一个建议:从目前呈现的效果来看,“怼”的效果可能还欠缺一点火候,希望后期可以“怼”得更好。
- 最终评审结果:通过
 暑期2020 [为 go-wechaty 设计实现插件体系] 结项报告
暑期2020 [为 go-wechaty 设计实现插件体系] 结项报告