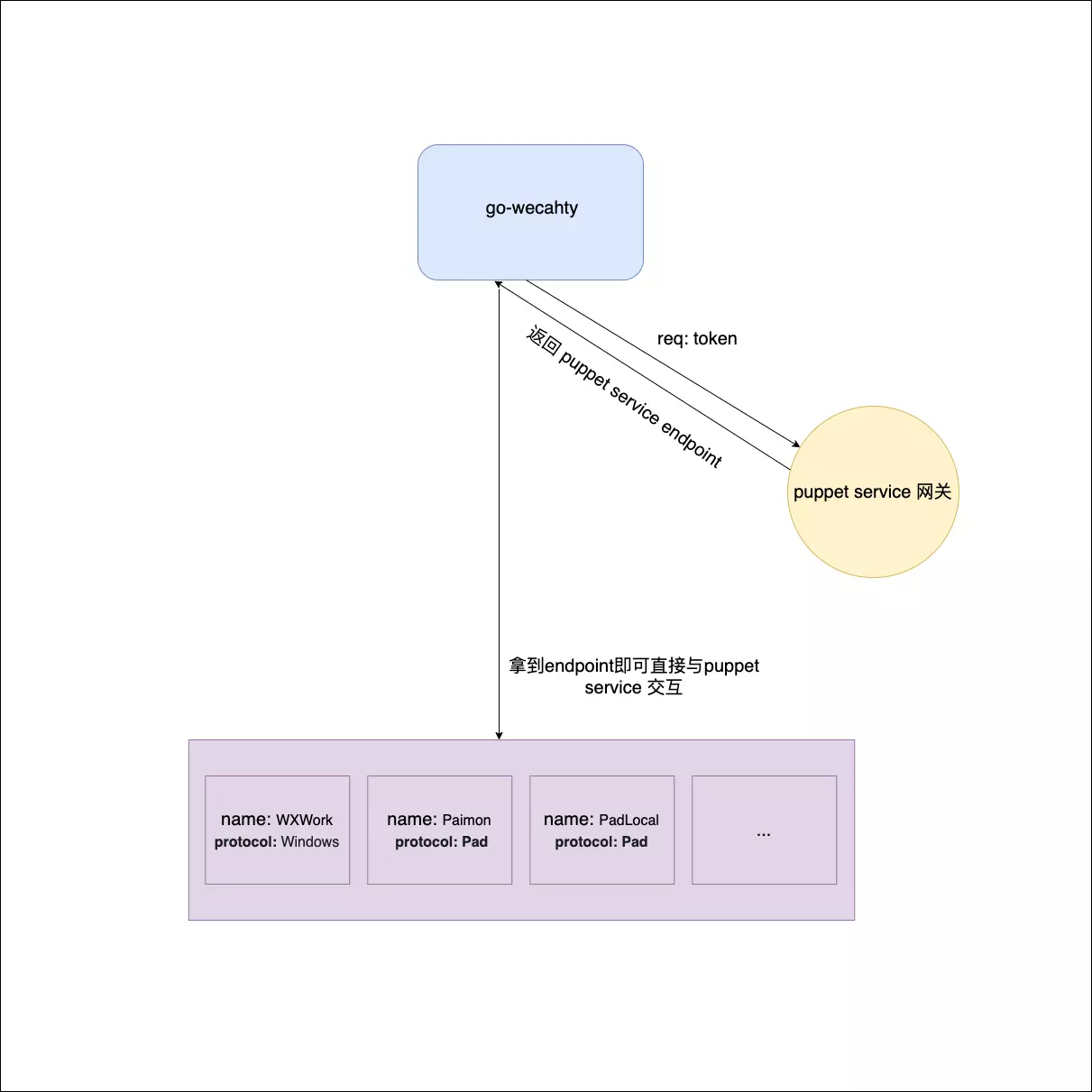
The Wechaty Puppet Service is running on top of the https://www.chatie.io service, which is open-sourced at here. It has been running for 5+ years on a Heroku free Dyno with Cloudflare CDN, everything works like a charm.
The Wechaty Puppet Service Server will register theirselves to https://api.chatie.io with their Wechaty Puppet Token, and the Wechaty Puppet Service Client will use this token for service discovery.
For example, the following shows that Wechaty started with a token:
export WECHATY_PUPPET_SERVICE_TOKEN=${TOKEN}
make bot
In the past 6 months, our online Hostie has been increasing fast, first from 1,000, then 2,000, and now it’s 3,000+ concurrency with a peek number around 3,500.
On April 15, 2021, we have a terrible service incident due to the limitation update of the Heroku and Cloudflare free servcies:
- Heroku limited our Dyno for no more than 1,000 concurrency WebSockets, which raised H11 - Backlog too deep errors.
- Cloudflare false report DDoS attatck and block all our visitors when we have 3,000+ WebSocket connections trying to connect to us during the server is rebooting.
Heroku Error: H11
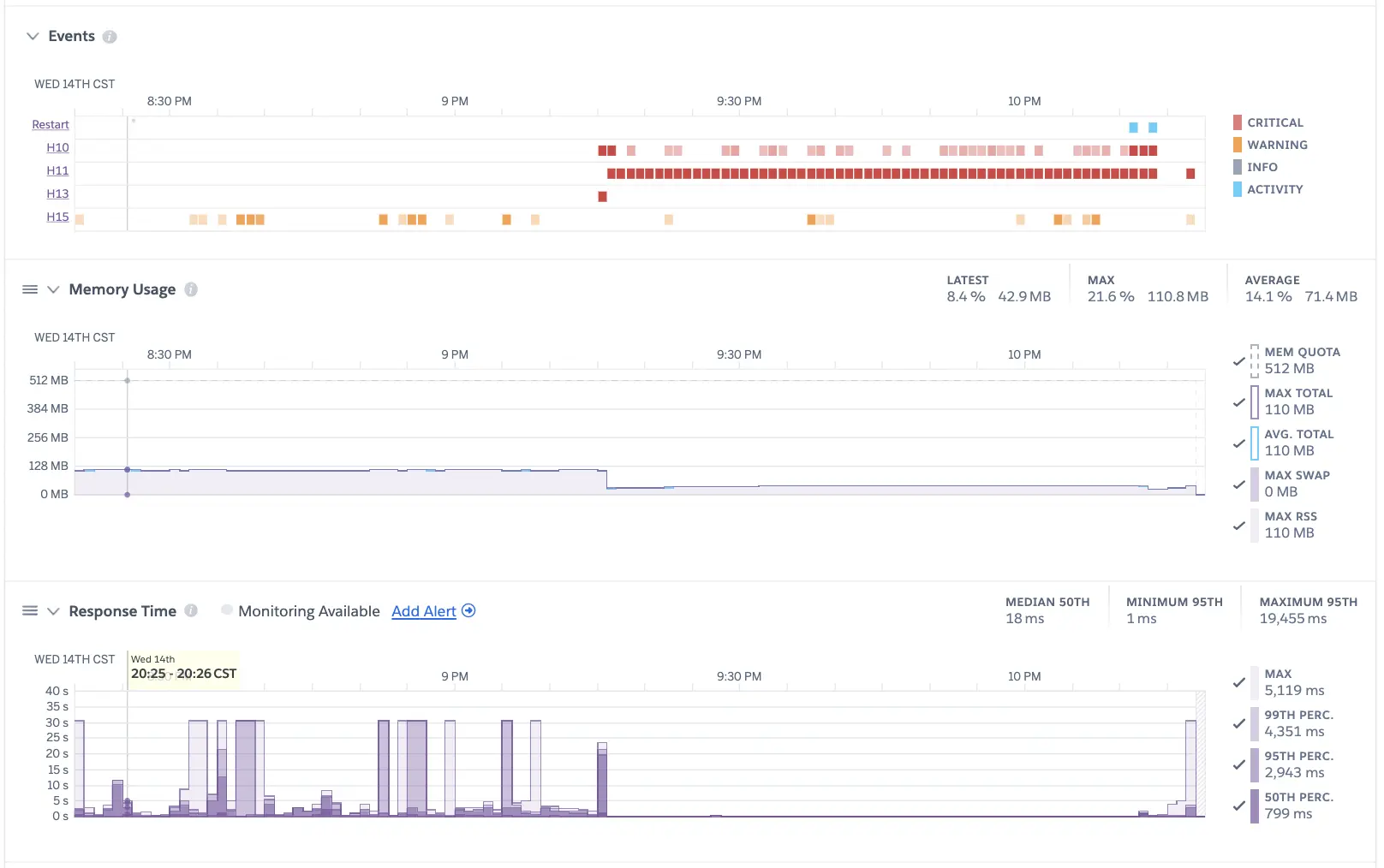
By using heroku logs -t -a chatieio, we can see the follow H11 and H10 error messages:
2021-04-14T14:11:03.885895+00:00 heroku[router]: at=error code=H11 desc="Backlog too deep" method=GET path="/v0/websocket" host=api.chatie.io request_id=59ec8c0c-aba6-4a7a-a7a1-c1d6ff798fc9 fwd="52.83.49.48,108.162.215.120" dyno= connect= service= status=503 bytes= protocol=http
at=error code=H11 desc=”Backlog too deep”
2021-04-14T14:12:01.619098+00:00 heroku[router]: at=error code=H10 desc="App crashed" method=GET path="/v0/websocket" host=api.chatie.io request_id=d0fa3403-5d6f-4f42-a2f9-e81de0bfb6c3 fwd="52.82.109.225,108.162.215.108" dyno= connect= service= status=503 bytes= protocol=http
code=H10 desc=”App crashed”
The Dyno status is totally a mess:
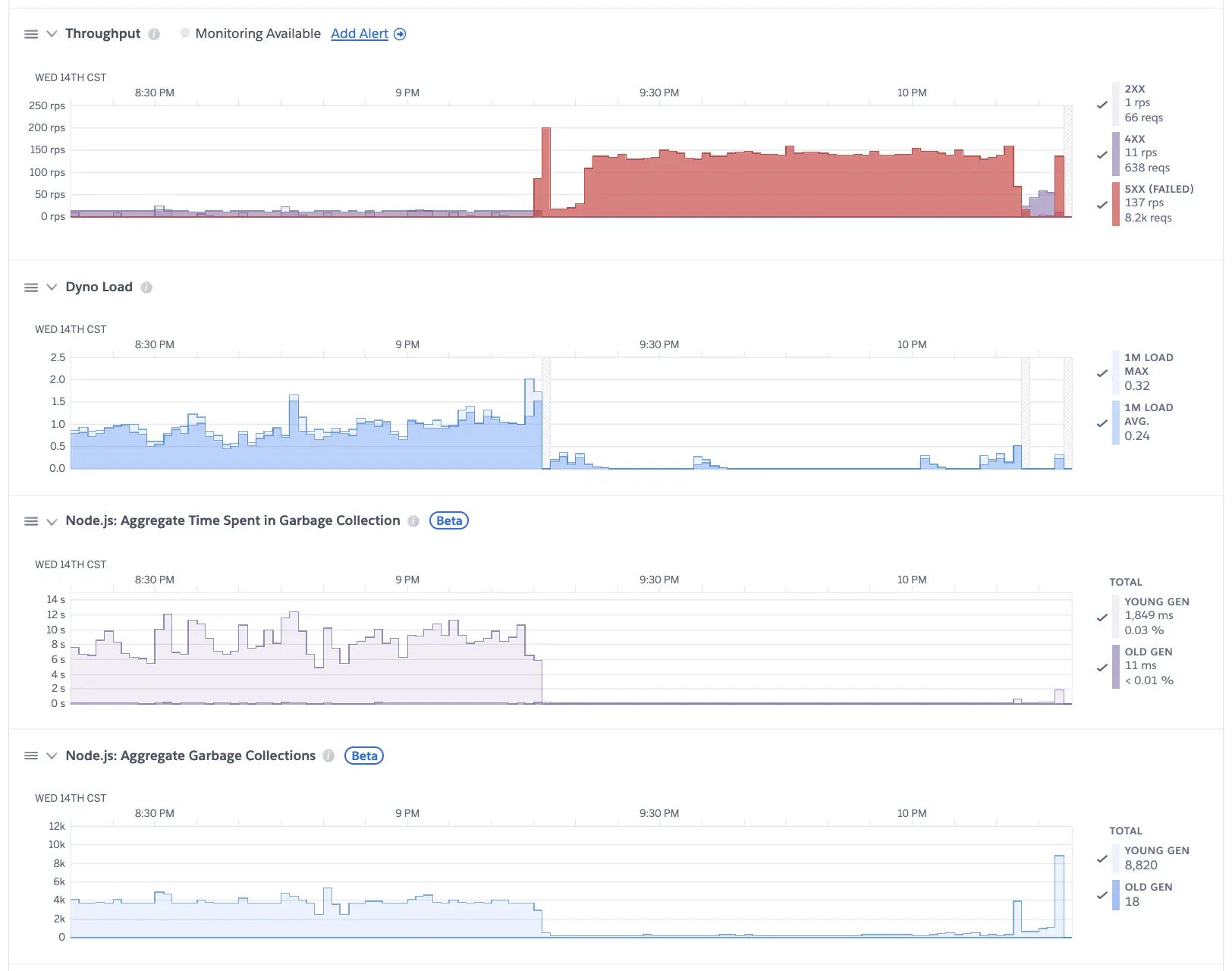
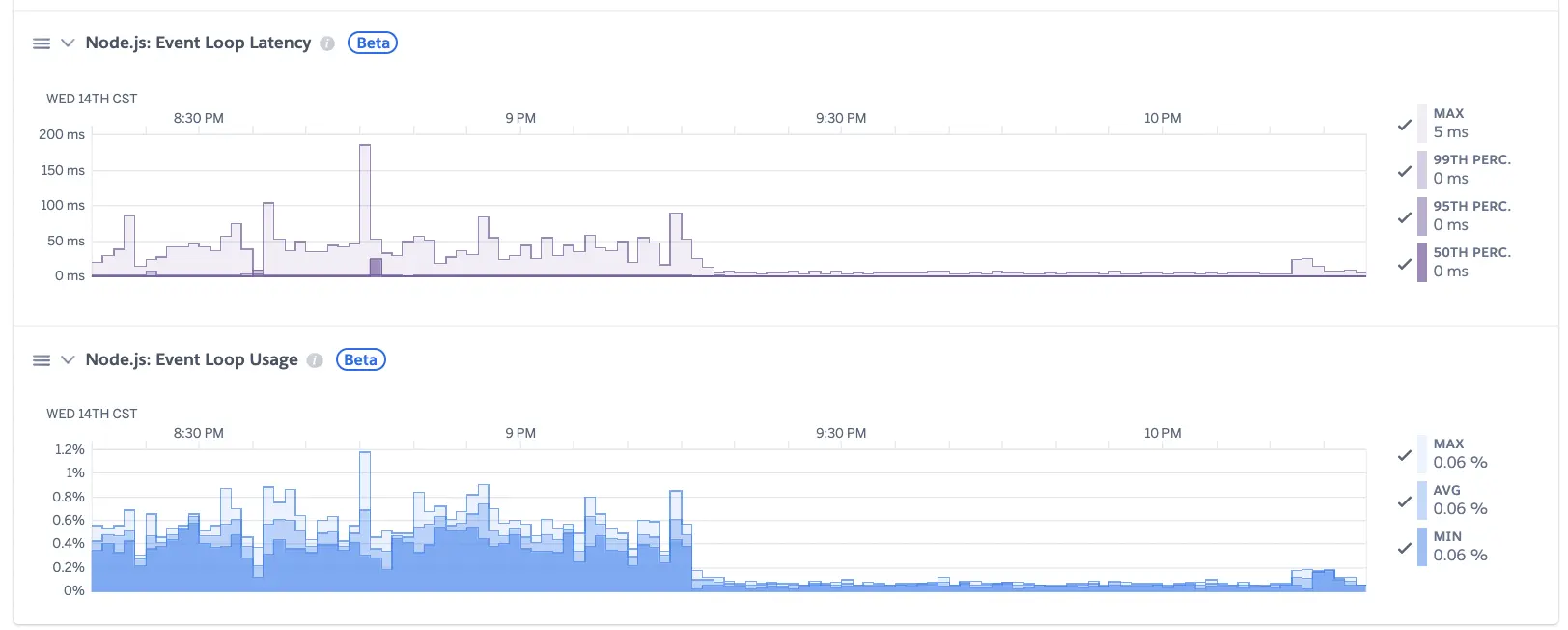
By reading the Does Heroku still limit Websocket connections?, @Owens, Feb 2019, we learned that the total WebSocket number of a single Dyno has some limitations:
- Oct 2013: 6,000
- Sep 2016: 1,500
- Heroku Router docs: 50 (!?)
Our concurrency has been over 3,000 for months:
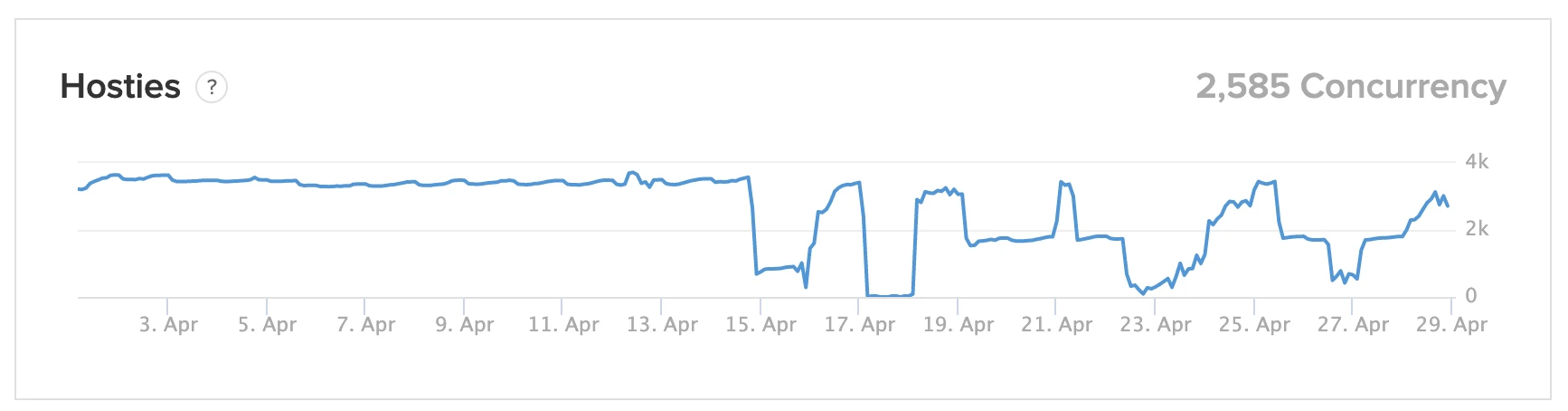
So I believe there must be a inforstructure update to the Heroku system, which caused my free Dyno can not support so may concurrency WebSocket connections any more.
I have to switch to the paid plan and create more Professional Dynos to support 3K+ concurrency, and I found that there needs at least four Dynos to prevent the H11 error, which means each Dyno can only have no more than 1K concurrency WebSocket connections.
Heroku Problem
- The Heroku Dyno fail with error H11 of a sudden.
- In the past, we can connect 3000+ WebSocket connections with a free dyno.
- From this week, it seems that we need 4 paid pro dynos to prevent the H11 error.
Heroku Solution (Workaround)
We use 4 dynos for our service for workaround.
Workaround Issues
Because the service is not designed for the horizon scale, so the query will fail 3 times with 1-time success on average.
01:00:20 VERB Wechaty wechatifyUserModules(Puppet#0<PuppetService>(ding-dong-bot))
01:00:20 VERB PuppetService start()
01:00:20 VERB StateSwitch <PuppetService> on(pending) <- (false)
01:00:20 VERB PuppetService startGrpcClient()
01:00:20 VERB PuppetService discoverServiceIp(puppet_donut_XXX)
01:00:20 WARN No endpoint when starting grpc client, 10 retry left. Reconnecting in 10 seconds...
01:00:30 VERB PuppetService discoverServiceIp(puppet_donut_XXX)
01:00:32 WARN No endpoint when starting grpc client, 9 retry left. Reconnecting in 10 seconds...
01:00:42 VERB PuppetService discoverServiceIp(puppet_donut_XXX)
01:00:43 WARN No endpoint when starting grpc client, 8 retry left. Reconnecting in 10 seconds...
01:00:53 VERB PuppetService discoverServiceIp(puppet_donut_XXX)
01:00:54 WARN No endpoint when starting grpc client, 7 retry left. Reconnecting in 10 seconds...
01:01:04 VERB PuppetService discoverServiceIp(puppet_donut_XXX)
01:01:05 WARN No endpoint when starting grpc client, 6 retry left. Reconnecting in 10 seconds...
01:01:15 VERB PuppetService discoverServiceIp(puppet_donut_XXX)
01:01:15 VERB PuppetService startGrpcStream()
01:01:16 VERB PuppetService onGrpcStreamEvent({type:EVENT_TYPE_SCAN(22), payload:"{"qrcode":"http://weixin.qq.com/x/AddMKwOGpxHRGRQNPWh5","status":2}"})
Setup an Azure Server for Chatie API Service
It seems that the Heroku service can not meet the requirements of Chatie API service any more, so we have to create a VPS to host the Chatie API service by ourselves.
It’s not hard for us to implemente this by the following steps:
- Create a Azure server with Debian Linux
- Install Docker
- Prepare https://github.com/nginx-proxy/nginx-proxy container: we found the
worker_connectionsin this container has been limited to1024, so we need this PR#973. - Build docker image for chatie/server
- Start
nginx-proxywith port80and443for the web service -
Start
chatie/servicecontainer with the followingdocker-compose.ymlconfig:version: '3.8' services: chatie-api: image: chatie-api container_name: chatie-api network_mode: bridge expose: - 8788 environment: - HTTPS_METHOD=noredirect - VIRTUAL_HOST=api.chatie.io,www.chatie.io - LETSENCRYPT_HOST=api.chatie.io,www.chatie.io - Change the DNS of
api.chatie.ioon Cloudflare from Heroku to our new Azure server.
After the above steps, the service back to normal. The Cloudflare DNS TTL is 600 seconds by default, so the hostie concurrency increased to 3k+ after 10 minutes (600s).
However, the system down again due to a Cloudflare HTTP DDoS protection, which has also never happened before.
Cloudflare False Alarm: HTTP DDoS
What I did before trigger the DDoS protection is that I stop the Chatie API server and restart it again.
This will cause all the client’s WebSocket connection to be closed, then every clients will start trying to reconnect immediatelly, which will cause 3K+ WebSocket new connection at the same time.
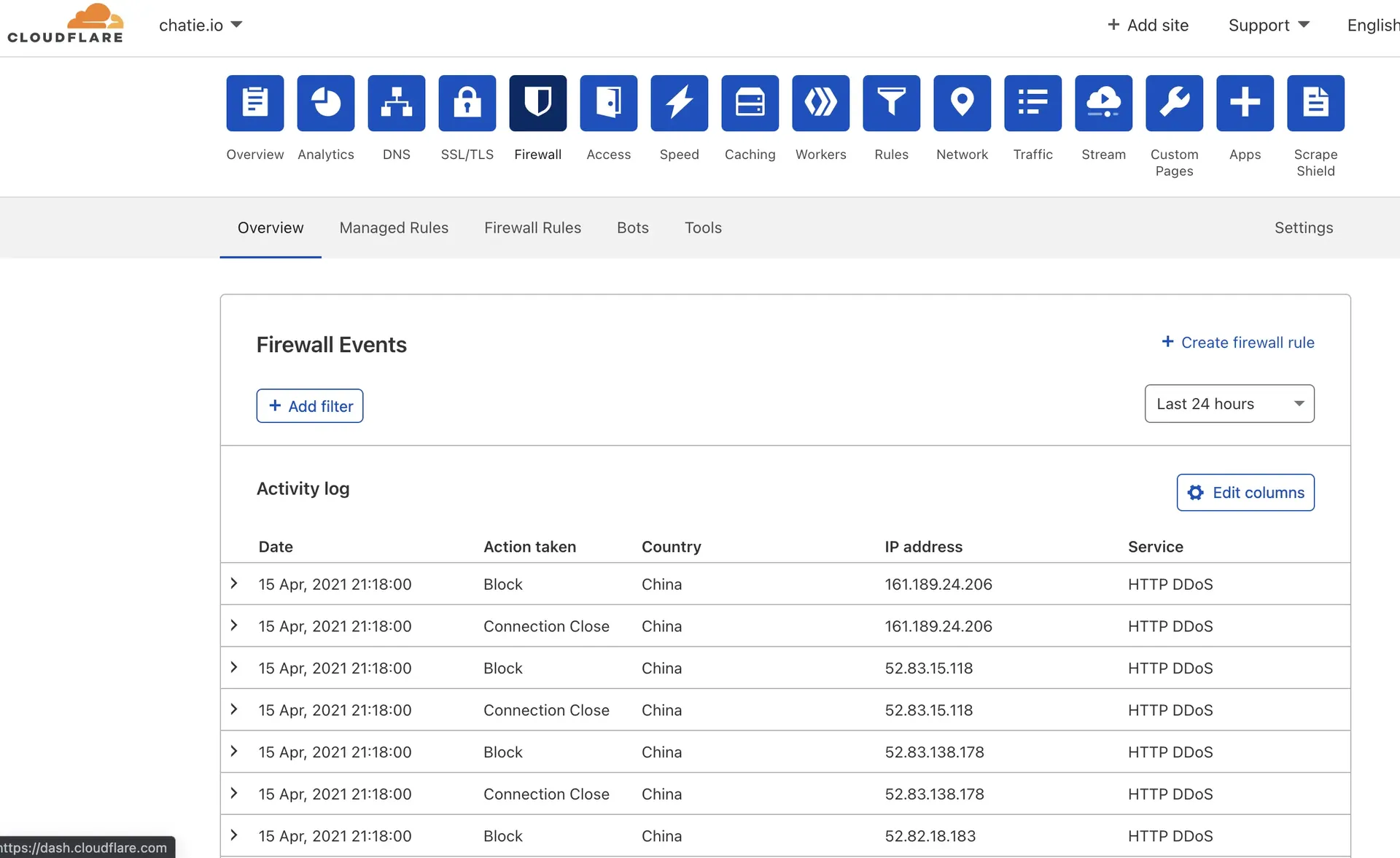
I try to add some Firewall Rules in the firewall settings to accept the traffic and bypass the HTTP DDoS protection, but have no luck to success.
So finally I have to disable the Cloudflare proxy feature, to let the traffic do not touch Cloudflare CDN anymore.
After all the traffic go to the Azure server directly, everything back to normal again.
Conclusion
I do not like to setup server by myself. I want to use Heroku and Cloudflare to save my time.
However, for now, our Chatie service have to run on my Azure box. I hope we can move this service back to cloud again, and soon.
The service down affect about 12 hours:
- Heroku workaround (service degrade) for about 8 hours
- Cloudflare false protection (service down) for about 4 hours
To-do list:
- Config to restart servers (Node & Linux) when the services run into unknown stautus
- Config DevOps for CI/CD
Issues
- Chatie.io server down Chatie/server#55
 重磅:使用UOS微信桌面版协议登录,wechaty免费版web协议重放荣光
重磅:使用UOS微信桌面版协议登录,wechaty免费版web协议重放荣光