
很高兴能分享前段时间折腾的小项目,一只熊猫头表情生成机器人。因为本熊是个很热爱meme文化的人,而在聊天过程中,我总是需要表情包来支撑起我匮乏的语言表达能力以及抒发我无法通过文字表达的感情。这次使用wechaty和paddlepaddle制作了一个根据人像生成对应熊猫头的表情包制作机器人。经本人不正经的测试,本表情包制作机器人可以给你的对话增加更多的乐趣,聊天室内外充满了快活的空气~
你可以在这里看到大致的效果
项目介绍和使用
项目的github仓库地址 在刚想到将wechaty与paddlepaddle结合的时候,其实是有很多的想法的,除了这个表情包生成器,还有游戏,交互写故事等想法,最后选择先做了这个表情包生成器,因为它足够简单却有趣,作为第一个试水作品最合适了。 简单介绍这个机器人的功能: 1.接收到人脸照片/视频会提取人脸,制作对应的熊猫头表情包 2.输入文字会给表情包的底部加上想要的文字
本项目使用的是没有使用token的网页登录的方式。因为一些个人原因整个项目分为两个大部分,一个是js端,用于分类消息类型,并向服务器端发送请求,这部分为wechaty的使用;另一个是django服务器端,负责处理js端发来的请求,制作表情包并返回结果,这部分则为paddlepaddle的使用。本项目基本上是采取解决不了问题就躲开问题的处理方式,所以有些地方的处理为了快速实践出功能,而采取了一些“非人类”的解决方法,还请大佬们见谅嘿嘿。
JS端,wechaty-getting-started目录下: set WECHATY_LOG=verbose set WECHATY_PUPPET=wechaty-puppet-wechat npx ts-node examples/advanced/Panda-Face-bot.js
Django端,PDjango目录下: python manage.py runserver 0.0.0.0:8080
框架图
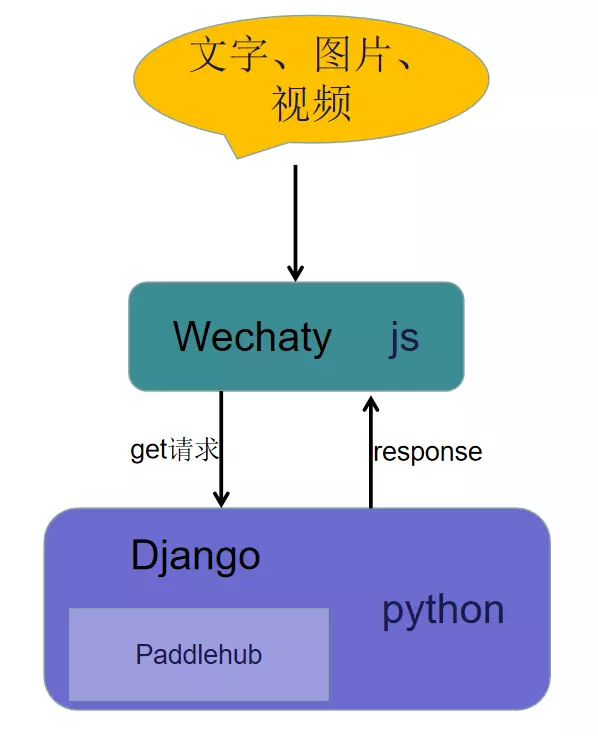
wechaty部分
前面说的“个人原因”其实是因为python版本的wechaty我一开始没搞定,所以不得已采用“非人类”方式将整体架构拆开为两部分。当熟悉python版本后,完全可以把整个项目用python实践出来。 Wechaty端,我直接魔改的官方的advance例子中的media-file-bot.js文件,增加了两个模块: 1.网络请求模块,因为我需要调用自己的django服务器,所以写了这一个模块,给自己的端口上发请求,然后处理返回的结果,返回表情包,或者告诉用户我没有在你发送的图片/视频中发现人脸 网络请求部分,为一个get请求。用于发送文本和图像信息。因为wechaty端和django端都部署在了本地,所以图像的信息只是图像在本地的保存地址。对于get请求响应的处理则更简单,django端在顺利处理图像后同样会返回图片的本地地址,wechaty端只需构建filebox,然后发送即可。
2.保存文字的模块,要针对不同的信息发出者,保存其对应的文字,结果保存在一个sender.json文件中 这个部分是为了给我们的表情包加上文字。即是当一个用户发送一个文本消息时,则将用户id和这个文本作为一个键值对保存起来,在收到图片消息后,根据图片消息的id来找到其对应的文本消息,将这两者打包发送给django服务器端。但是这里遇到的一个问题:这个请求不太好解析中文字符。服务端受到的text会变成乱码,所以这里的“非人类”的处理方式是当收到文本消息时将键值对保存到json文件里。而在发送请求时,则发送用户的id(用户的id是没有中文字符的);在服务端则根据id从json文件里查找id对应的文本。
服务器端部分
django的部分非常的简单,在view中添加一个处理get请求的方法就好,这部分处理一下请求中的数据,根据数据去调用pandaFace脚本就好。下面主动点讲一下pandaFace脚本。
pandaFace脚本则是处理图像的主文件,提供了处理图片和视频的方法.大致的流程如下:
1.熊猫头表情包的人脸去除和人脸定位
这里需要使用paddlehub中的两个模型,一个是ace2p,一个是face_landmark_localization。通过这两个模型来获取作为模板的原表情中“人脸”的位置,我们之后处理用户发来的人脸,要根据这个标准来缩放,并绘制到指定位置上。
2.接收到的图片的人脸的提取和缩放,处理到灰度图,适当添加对比和亮度
同样使用上述的两个模型处理用户发来的肖像照,然后进入我花费时间最长的步骤——调整颜色。
因为光照等原因,把图像转为灰度图的任务始终无法达到理想的效果。这里尝试了亮度、对比度、直方图等统一的方式做了一些处理,大家也可以进行测试。另外我觉得最可行的方法是直方图匹配,这方面值得继续改进。
亮度调节对比
 对比度调节对比
对比度调节对比
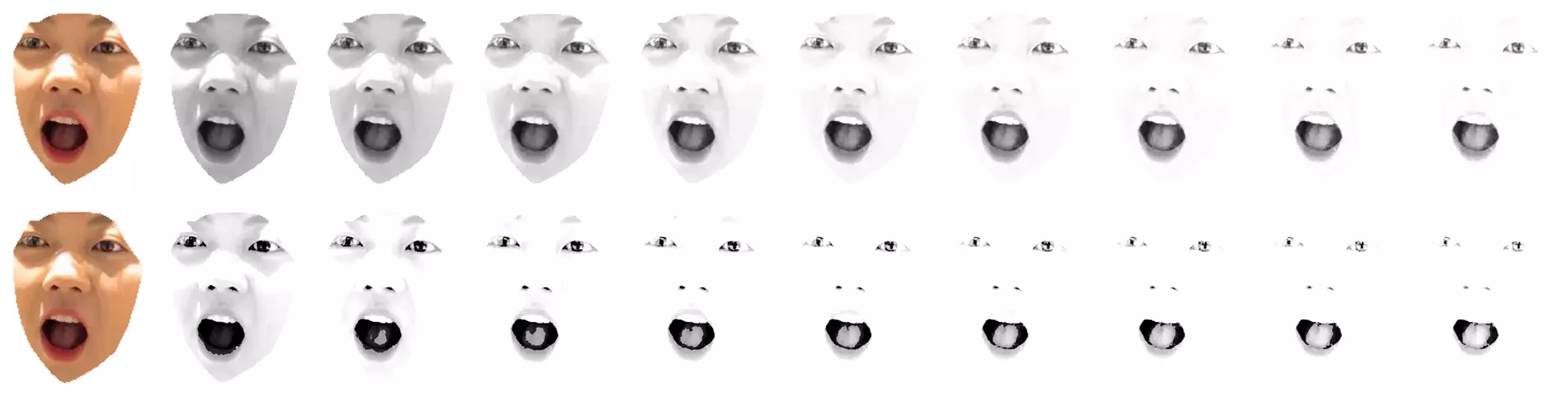 gamma方式调节histogram调节对比
gamma方式调节histogram调节对比
 这部分试了很多个参数,但是对于不同的图片不太好做到统一,所以想到了直方图匹配(histogram match),但是这部分实验的图找不到了,之后补上,直方图匹配的代码也在脚本中提供了,但是默认并没有开启。
直方图匹配的方法可以把人脸映射到和原版的表情包大概同一个色调,但是缺点是,直方图匹配的方式会损失细节,这样会出现跃迁式的像素变化,很丑,所以可能采用直方图匹配之后要做更多的处理。
这部分试了很多个参数,但是对于不同的图片不太好做到统一,所以想到了直方图匹配(histogram match),但是这部分实验的图找不到了,之后补上,直方图匹配的代码也在脚本中提供了,但是默认并没有开启。
直方图匹配的方法可以把人脸映射到和原版的表情包大概同一个色调,但是缺点是,直方图匹配的方式会损失细节,这样会出现跃迁式的像素变化,很丑,所以可能采用直方图匹配之后要做更多的处理。
3.把2中的人脸根据1中的定位,贴到1中的熊猫头上 opencv的简单操作,嘿嘿~ 4.添加文字 针对文字的方面,也通过归一化图片尺寸和一定的规则即可简单的添加在图片上。
总结+改进完善方向
最终版本中没有开启直方图匹配(提供了这部分的代码,只是没有开启),但是还是可以尝试,直方图匹配后的结果图像”质量”更差,但是表情包的精髓不就是糊吗?糊到一堆水印,糊到满是包浆。
最后统一采用了2.2的对比和3的亮度,如果要改进的话,应该还是可以提升一下直方图匹配的效果。
除了人脸处理模块,其他的部分需要改进的大概是舍弃掉这种js+django服务器的模式,这样的效果有点慢。在熟悉wechaty的python版本后,则可以直接抛弃这一方法。
在频繁给django发送请求后,server端的cpu和内存”爆炸”,这部分不确定是django的问题还是Paddlehub的问题,目前这个问题似乎没有再出现(真是让人迷惑)。
作者: ninetailskim,始于兴趣 陷于技术 忠于瞎搞
This post is also available in English.
 How to Build a Panda Face Meme Generator with PaddlePaddle and Wechaty
How to Build a Panda Face Meme Generator with PaddlePaddle and Wechaty