
销售在跟客户沟通的过程中,会出现回复客户不及时,以及回复时存在错别字和病句的现象。所以HR部门要利用机器人记录这种情况,用于计算销售人员的绩效。11月份我完成了销售回复报表,管理者可以看到某销售的表现,某顾客是否被妥善回复,以及销售超时回复的具体情况。
一、交付
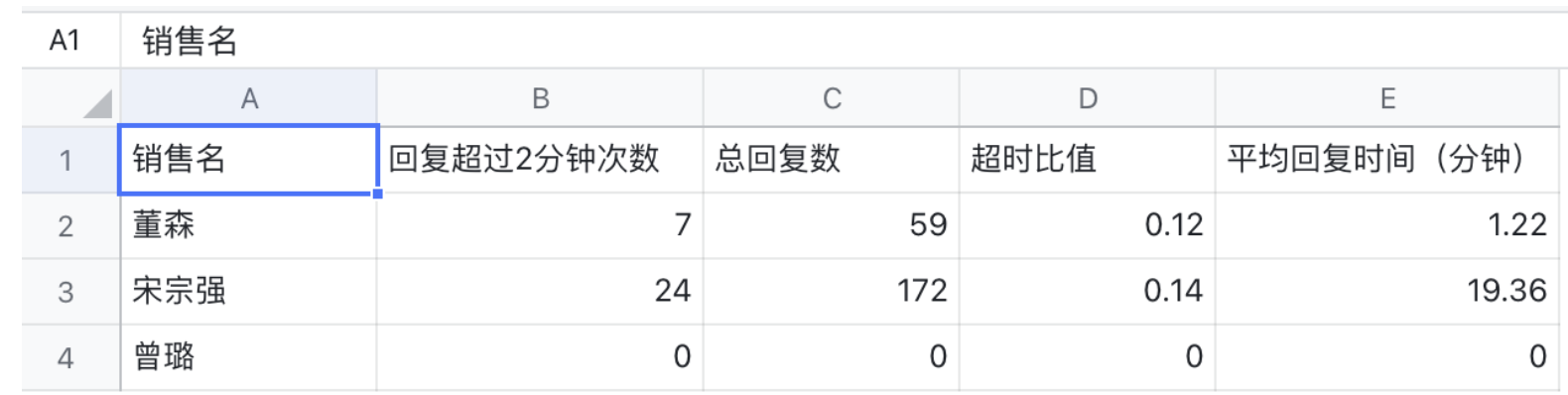
销售视角
为了评估某个销售的表现,统计销售在所有负责群的指标
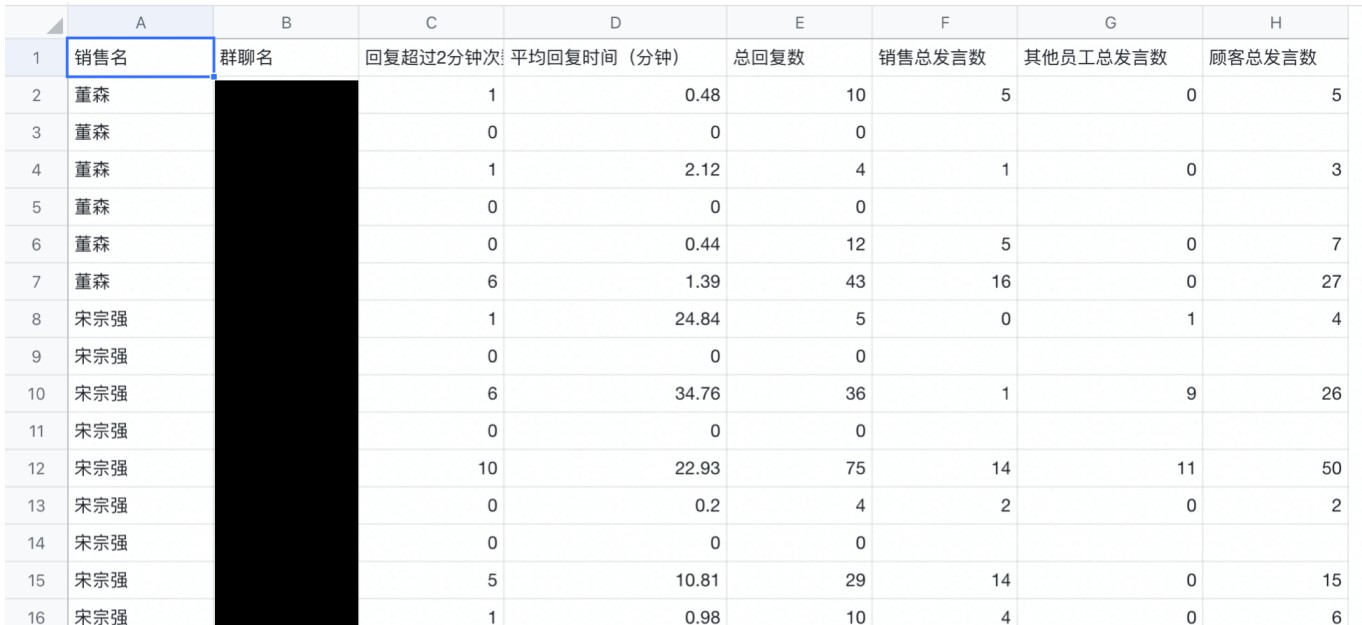
群聊视角
为了评估某个销售的表现,统计销售在所有负责群的指标
群聊细节
为了评估某个销售的表现,统计销售在所有负责群的指标

影片
报告
二、实现
我们使用专门的sales-assistant微信手机号,作为机器人的帐号。当销售把机器人拉群后发出第一则消息,机器人会自动将该群储存在销售-群组列表内。对于所有捕获到的消息,按照Wechaty的格式存入OpenSearch数据库内。我们将每个群聊的消息提取出来分析超时回覆情况,并在每天提取该天的销售回覆结果,做成报表,推送到工作群内。
将业务逻辑转为实现
如何将业务逻辑转成代码?这是最不确定的环节,很考验程序员跨领域的了解。但通常这种能力是隐性的,无法透过三言两语显性化表述出来,既有方法是靠经验和交流。我们如何让这个过程变得更有序?。句子互动是一个规模逐渐增大,年轻有活力的创业公司。这代表着存在许多未被流程化的跨部门任务,也提供我很好的一课。
根据场景矛盾提需求
首先,在確定接任務前,佳芮(CEO)和康龍(HR)已經對需求寫出了較為清楚的背景(why), 目標(what), 和附加影響(so what):
背景
- 销售与客户售后沟通时,会出现回复不及时,回复病句等现象
- HR部门要利用机器人记录这种情况,用于计算销售人员的绩效
目標
- 实时记录群内聊天记录
- 分析销售回复不及时
- 分析销售说话时的错别字和病句
附加影響:
- 错误分析结果加进销售绩效以让他们有意识地减少自己语句的错别字和病句
根据需求熟悉业务场景
做为公司新人的我,希望对销售场景的细节有更高的感知。这包含一般沟通流程是什么、什么算是好或坏的流程、对于机器人而言应该先优化哪些点。
经过和佳芮、张佳(市场)的讨论后,得到当前主要的痛点是无法对销售回覆不及时的情况做统计、分析、可视化、与提醒。这个过程耗费了太多人力。相比于错字错句而言,超时回覆的问题是比较好定义的,实现的逻辑应该也比较简单。所以应该先专注在这个点,当能跑通一个数据驱动的闭环,就可以专注在更多的逻辑和优化。
另外我也发现到,要将讨论过程逻辑化并非单纯之事,因为涉及到许多分支与业务逻辑。
将需求转为设计
经过以上的领域调研,需要开始转换成实现。
我的伪代码策略,是先定义静态的数据结构,再根据这些变量,定义判断成败的业务逻辑,而不涉及任何执行的指令。这种对象式+函数式的描述知识的方法,可跳脱具体的实现方式,帮助在更早的阶段针对这段逻辑debug,初步评估实现的复杂度、以及扩展性。
数据结构方面,我定义了角色类别以及销售-指标列表。在逻辑方面,我定义了超时的评判标准。实际上,这个列表在后来的沟通中又调整了几次,但大体上是没有差距太多的。
Variables
roles :{sales,juzi-employee,customer}
sales_record : {
"name:Kevin" :{
"criteria:late_reply": {
count: number
messages: [
msg_obj1,
msg_obj2,
...
]
}, ...
"criteria:low_replies": {
count: number
messages: [
msg_obj1,
msg_obj2,
...
]
}
},
"name:Alice" :{
}, ...
}
Logic
for each msg from customer, if reply time of sales > t, update sales_record
掌握实现端后与需求端再次沟通
拿了这个表后,我带着比较清楚的头脑找佳芮确认产出的形式,也就是报表要有的表项。这里注意不曝露太细节的实现,更重要的是确认产出是使用者需要。和佳芮在白板上画图讨论的过程很好玩 xD,因为在实现端心里有底,能够接受任何需求端提供的额外信息,干净清澈的感觉。
从业务中发现矛盾、到提出需求、再到实现,这需要经过一长串转化过程。若写PR的人不像佳芮和康龙有技术背景,提出来的需求很可能无法或较难落实。但当技术人员要修改需求建议时,又可能因为看不到某需求对业务有多痛,而无法做决策。所以在需求端与实现端之间的交流与合作模式,是重要的课题。
Wechaty 机器人实现细节
wechaty 整体是基于非同步函数实现的,所以函数主体是写在onMessage内的。但因为在函数内需要再调取Opensearch 非同步的 API , 容易写出两层或三层以上的非同步函数。经过探索后,可行的框架如下:
async function onMessage(msg) {
var room_name = await msg.room().topic(); //
var value = await client.get({ //get sales-customer tree
id: doc_metric_id,
index: index_metric
})
//if detect new room, create room and modify value
//modifying sales-customer tree
//...
//...
put_document(index_metric,value,doc_metric_id); //put new sales-customer tree into OpenSearch
//modify msg into new_msg object
//...
//...
put_document(index_name, JSON.stringify(new_msg), new_msg.id) //put new_msg into OpenSearch
}
超时回复实现细节
超时回覆的定义是:顾客首次发消息到销售首次回覆的时间间隔,大于某门槛 time_threshold 。我们将此逻辑转成对 to_reply 的状态的维护。
if(is_from_customer(response)){
if(to_reply===false){ //customer 1st request
to_reply = true;
to_reply_msg_time = response.time
}
}else{ //is from employee
if(to_reply===true){//employee 1st reply
to_reply = false
var replied_msg_time_sec = (response.time - to_reply_msg_time)
if(replied_msg_time_sec > time_threshold)over_2_mins_count+=1;
}
}
OpenSearch 实现细节
OpenSearch可储存结构化数据,并透过不同索引搜索获得,其中透过cluster和shard维护数据的冗余性,是ElasticSearch的開源版本。對於初學者(我),難度在於以下幾點:
- 正確使用query language來提取想要的數據。
- 透過 mapping, 跳脫默認的 indexing 策略。
在分析的过程中,需要从Opensearch提取当天某room下的所有信息,按照时间排列。这里有两个搜索条件:第一是群聊名,第二是当天的时间范围。这种 And 的逻辑,可以透过 compound query 来实现。在提取出數據後,要經過排序,這裡用 sort 實現。
var last_day_messages = {
sort:[
{"payload.timestamp":{"order":"asc"}}
],
size:1000,
query: {
bool:{
must:[
{match: {"payload.roomInfo.topic.keyword":room
}},
{range:{
"payload.timestamp": {
gte: "now-1d/d",
lt: "now/s"
}
}}
]
}
}
}
需要特别注意不同字段的层级。例如 sort 和 query 是在同一层级, bool 是在 query 字段内,最后整包数据会被作为 query 参数传入 client.search 的 API 。这两个 query 不能混淆。
var response = await client.search({
index: index_name,
body: query,
});
对于这种未知的、不熟悉的查询语言,需要在瞄准对应文档的基础上,建立快速调适的工作流,方可有加乘的效率。
还有额外几点需要注意:
-
把重要的document备份或保护好,不要误删数据。
-
message字段中的_payload自断要改成payload, 才能顺利被Opensearch的Dashboard解析。
三、下一阶段工作
-
飞书自动提醒与警告
-
拓展优化各个指标
 成功结项!大学生的一小步,开发者的一大步
成功结项!大学生的一小步,开发者的一大步