
Greedy decoding is too brittle, sampling is too random
Confident-Cluster Decoding (CCD) keeps only the tokens the model is truly confident about, exposes all top contenders, and turns that “soft uncertainty” into something coding agents and tool-calling systems can actually reason about.
1. The Moment I Realized Greedy Decoding Was Lying to Me
Like many people building with large language models, I started with the usual recipe:
temperature = 0topK = 1candidateCount = 1seedpinned to a constant value
Greedy decoding. No randomness. No drama.
Especially for code generation and tool calling, this feels like the “right” choice:
- I want deterministic behavior.
- I want minimal hallucination.
- I want valid JSON, compilable code, and stable outputs I can safely automate around.
In my FireGen project, I use Gemini to:
- take a user prompt + a schema,
- reason step-by-step about how to fill that schema,
- and output a strict JSON object for a REST API call.
With temperature = 0, topK = 1, and a fixed seed, it worked really well.
Most of the time the model behaved like a perfectly deterministic machine.
But sometimes, very rarely, I noticed something weird:
Same prompt, same model, same parameters —
and the model produced a slightly different answer.
Not a huge difference, but enough to matter if you care about strict behavior.
So I started asking: “Wait, I’m using greedy decoding. Where is the randomness coming from?”
That’s how this whole idea started.
2. What’s Actually Going On Under the Hood?
Even with “no randomness” in the sampling step, there’s still a lot of non-determinism inside a modern LLM stack:
- Parallel floating-point operations are not associative. The order of additions/multiplications can change the final bits.
- Different hardware / kernels / compilers may produce slightly different logits.
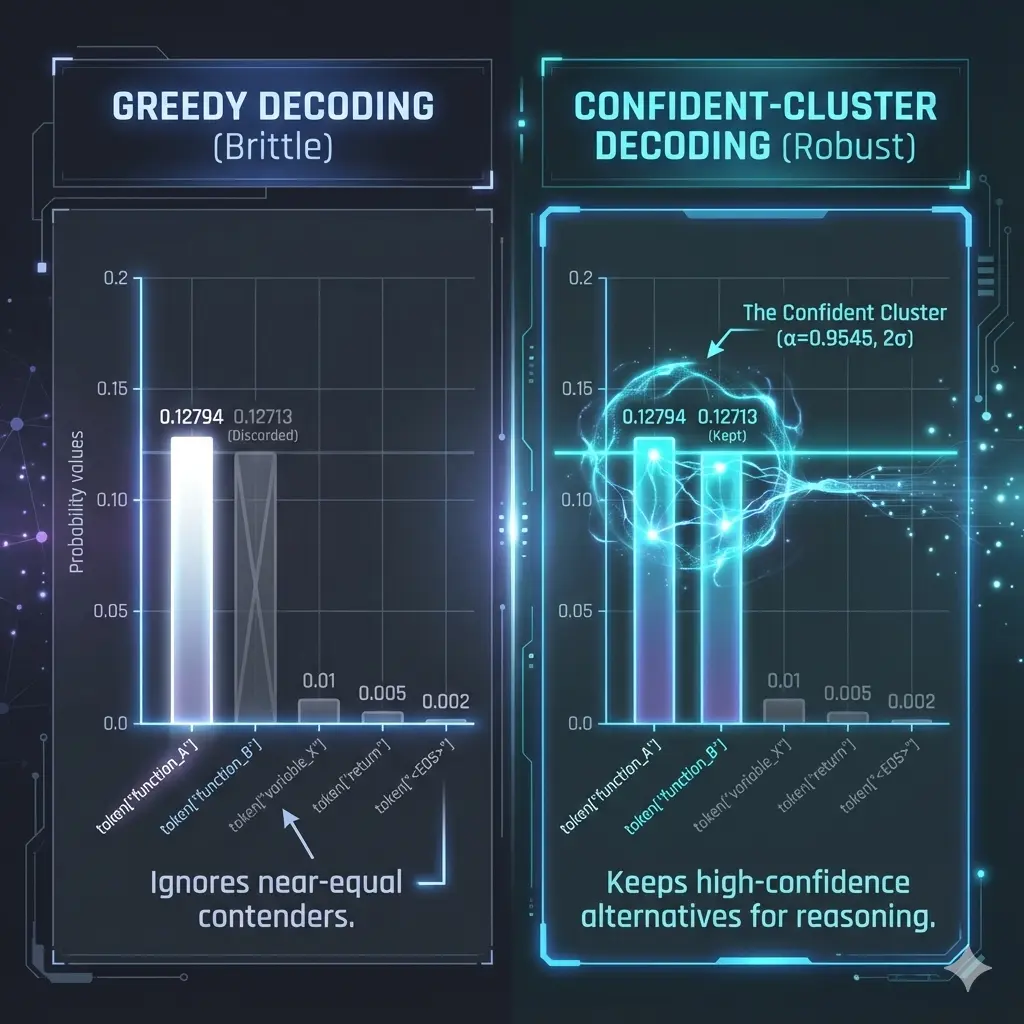
- If two tokens have probabilities like 0.12794 vs 0.12713 (typical for top-1 vs top-2 tokens in modern LLMs), a tiny numerical nudge can flip which one wins.
From the model’s perspective, both tokens are basically equally good.
From greedy decoding’s perspective, this becomes a hard, brittle choice:
- If token A barely wins → we always pick A.
- If token B barely wins (due to tiny numeric changes) → we always pick B.
In other words, greedy decoding is pretending there is exactly one “right” answer, even when the model’s own distribution is screaming:
“Actually, I’m not sure. I have a few candidates I like almost equally.”
This mismatch is the core problem:
- Greedy decoding discards all uncertainty.
- Sampling reintroduces randomness from the tail.
For developers building coding agents and tool-calling systems, that’s a bad trade-off.
3. The Realization: Don’t Just Pick One Token — Keep the Whole Confident Cluster
Once I started thinking in probabilities instead of just “top-1 vs sampling”, the idea became obvious:
At each decoding step, instead of pretending there is exactly one winner,
grab the whole set of tokens whose probabilities are almost as high as the top token.
This led to the core concept:
Confident Cluster
At a given step t:
- Let
P_maxbe the probability of the top token. - Define a threshold
αin(0, 1]. For example,α = 0.9545(≈ two-sigma coverage). - Define the confident cluster:
In plain English:
“Take the top token, then include any other token whose probability is at least 80% of that top token’s probability.”
This cluster has nice properties:
- It’s small but meaningful.
- Every token in it is high-confidence, relative to the model’s own belief.
- It automatically adapts:
- If the model is very confident → cluster size is often 1.
- If the model is uncertain between a few options → cluster contains multiple tokens.
And then came the algorithm:
🧠 Confident-Cluster Decoding (CCD)
Use the confident cluster at every step instead of just a single argmax token or a large sampling set.
CCD doesn’t throw away the uncertainty. It exposes it.
4. How CCD Works (Without the Math Headache)
You don’t need to be a theoretician to understand CCD. The mental model is simple.
Assume your LLM API can give you, for each step:
- The top K tokens, and
- Their log probabilities.
Then you can turn that into CCD with just a few lines of logic.
Step 1: Get top-K candidates
probs = softmax(logits) # or use logprobs from the API
top_probs, top_indices = topk(probs, k=top_k)
p_max = top_probs[0]
Step 2: Build the confident cluster
alpha = 0.9545 # two-sigma coverage
threshold = alpha * p_max
mask = top_probs >= threshold
cluster_indices = top_indices[mask]
cluster_probs = top_probs[mask]
Now cluster_indices is your confident cluster.
Step 3: Decide how to use the cluster
This is where CCD branches into different modes, depending on your use case.
4.1 CCD-Deterministic (Greedy but Honest)
-
Choose the top token, as usual:
chosen = cluster_indices[0] # argmax -
But also keep
cluster_indicesandcluster_probsaround as metadata.
You now have:
- The exact same output as greedy decoding, but
- Extra information about how uncertain each step was, and
- Which other tokens were almost equally strong candidates.
You can use this to:
- Flag fragile positions (cluster size > 1 near a schema boundary).
- Trigger extra validation when the model is uncertain.
- Log uncertainty for debugging and analysis.
4.2 CCD-Cluster Sampling (Controlled Diversity)
Instead of sampling from the entire distribution (which includes low-probability junk), you:
-
Re-normalize probabilities inside the confident cluster only:
q = cluster_probs / cluster_probs.sum() chosen = random_choice(cluster_indices, weights=q)
This gives you high-confidence variety:
- Great for generating multiple plausible code snippets or refactorings,
- Without dipping into hallucination-prone low-probability tokens.
4.3 CCD-Branching (Multi-Path Reasoning)
At key positions (e.g., early in the output, or around important decisions), you can:
- Branch over all tokens in the confident cluster,
- Decode forward on each branch,
-
Then select the best branch based on external checks:
- For code: run unit tests, static analysis, or linting.
- For JSON: check schema validity.
- For QA: use majority vote or minimum Bayes risk.
This gives you an agent-style “explore top plausible options, then verify” workflow.
5. Why CCD Is a Big Deal for Coding Agents & Tool Calling
Most decoding research historically has focused on open-ended natural language:
- Chat responses
- Stories
- Summaries
- Dialogue
In those domains, sampling-based methods like top-p, typical decoding, or contrastive search make a lot of sense. You want:
- Fluent, varied text,
- Less repetition,
- More creativity.
But coding agents and tool-calling systems live in a different world:
- A single bad token can break everything.
- Structural correctness is mandatory.
- Hallucinations are rarely “harmless.”
CCD is designed for this world:
-
It stays near the peak of the distribution.
You never sample from obviously low-probability tokens. -
It embraces uncertainty instead of hiding it.
You don’t pretend there’s only one right token when the model is torn between several. -
It plays nicely with deterministic workflows.
CCD-Deterministic lets you keep greedy decoding but wrap it in uncertainty awareness. -
It gives agents something to reason about.
The cluster can guide:- branching,
- validation,
- when-to-ask-a-human decisions,
- and more.
If you’re building:
- code copilots,
- auto-refactoring tools,
- schema-based tool callers,
- workflow orchestrators,
…then CCD is a decoding layer that actually understands your priorities.
6. How Is This Different from top-k, top-p, typical, min-p, etc.?
If you’ve been following decoding research, you might ask:
“Isn’t this just another truncation method?”
Yes and no.
CCD is related to several known ideas, but it has its own emphasis.
vs. Top-k
- Top-k: “Take exactly k most probable tokens.”
- CCD: “Take all tokens whose probability is at least
α * P_max.”
Top-k doesn’t care whether token #k is way less probable than the top token.
CCD explicitly enforces a relative confidence relationship.
vs. Top-p (nucleus sampling)
- Top-p: “Smallest set of tokens whose cumulative probability ≥ p.”
- CCD: “All tokens whose probability is close to the top token’s probability.”
Top-p can include low-probability tokens in flatter distributions, as long as they help reach the cumulative mass threshold. CCD never does that.
vs. Epsilon / Min-p Sampling
Some recent work proposes min-p or epsilon sampling:
- Use probability thresholds (absolute or dynamic) to define a sampling set.
- These are very related and worth citing in an academic context.
But in practice, most of those methods are still optimized for:
- sampling, not deterministic decoding,
- improving natural language generation, not coding / tooling reliability.
CCD’s main goals are:
- Deterministic-mode compatibility (CCD-Deterministic),
- Token-level uncertainty exposure, and
- Serving as a building block for agents, not just a sampler.
vs. Typical / Contrastive Decoding
- Typical decoding is about the “typical set” of surprisal given entropy.
- Contrastive search is about mixing LM scores with hidden-state-based penalties to avoid degeneracy.
Both are powerful, but they operate at a different conceptual layer. CCD is:
- simpler,
- purely probability-based,
- and more directly plugged into code & schema-centric workflows.
7. Where This Idea Came From (FireGen Origin Story)
The story in one paragraph:
- I was building FireGen, a Firebase Extension that uses LLMs to turn prompts into REST API calls using Vertex/Gemini models.
- I used fully deterministic decoding (
temperature = 0,topK = 1, fixedseed) because any non-determinism in schema generation is dangerous. - It worked well — until I noticed rare nondeterministic outputs despite “no randomness.”
- Investigating further, I realized: the model is often nearly indifferent between several tokens. The nondeterminism wasn’t a bug; it was a symptom of hidden uncertainty.
- That led to the question: “If the model likes several tokens almost equally, why am I forcing it to pick exactly one and pretend the others don’t exist?”
Confident-Cluster Decoding is my answer to that question.
FireGen was just the first lab where I saw this. The more I think about CCD, the more I believe it’s relevant to any serious coding agent or structured LLM system.
8. Our Bigger Plan: From Blog Post → Open Source → Research Paper
This blog post is just step 1.
Here’s the bigger plan:
-
Formalize CCD properly
We already have a draft academic paper spec’d out in Markdown / Quarto, with:- formal definitions,
- CCD variants,
- implementation details,
- and an experiment plan across code generation, QA, reasoning, and JSON tasks.
-
Run solid experiments
Evaluate CCD on:- code benchmarks (HumanEval, MBPP or similar),
- factual QA,
- math reasoning (GSM8K-style),
- structured JSON generation tasks.
Compare against:
- greedy,
- top-p,
- top-k,
- min-p / epsilon sampling,
- typical decoding (if available).
-
Open-source reference implementation
Implement CCD as a small, drop-in layer around:- Gemini (via its logprob APIs),
- an open-source stack (Llama/Mistral via vLLM / HF Transformers).
Ideally, CCD turns into something like:
from ccd import CCDDecoder decoder = CCDDecoder(model, alpha=0.85, top_k=20, mode="deterministic") output, metadata = decoder.generate(prompt) -
Submit a paper (arXiv + conference)
Focus on the intersection of:- LLM coding agents, and
- decoding / uncertainty / reliability.
-
Use CCD in real coding agents
Integrate CCD into:- code-writing agents,
- test-driven repair loops,
- schema-based tool calling,
- and eventually higher-level multi-agent systems.
If this resonates with you, you’re exactly the kind of person I’d love to collaborate with.
9. How You Can Play With CCD Today
Even without formal library support, you can already experiment with CCD if:
- Your LLM API gives you top-K logprobs at each step, or
- You’re running your model in an environment like vLLM or Transformers where you control the decoding loop.
Minimal CCD-Deterministic Sketch
def ccd_greedy_decode(model, tokenizer, prompt, alpha=0.9545, top_k=10, max_tokens=256):
tokens = tokenizer.encode(prompt)
clusters = [] # store step-wise cluster metadata
for _ in range(max_tokens):
logits = model(tokens)[-1] # last-step logits
probs = softmax(logits)
top_probs, top_indices = topk(probs, k=top_k)
p_max = top_probs[0]
threshold = alpha * p_max
mask = top_probs >= threshold
cluster_indices = top_indices[mask]
cluster_probs = top_probs[mask]
# deterministic choice == greedy
next_token = cluster_indices[0]
tokens.append(next_token)
clusters.append({
"cluster_tokens": cluster_indices,
"cluster_probs": cluster_probs,
"chosen": next_token
})
if next_token == tokenizer.eos_token_id:
break
text = tokenizer.decode(tokens)
return text, clusters
You can start by:
- Logging
len(cluster_tokens)at each step. - Checking where the model had low vs high uncertainty.
- Comparing CCD-Deterministic to standard greedy and seeing where they diverge under small perturbations.
10. Closing Thoughts: Decoding as a First-Class Design Space
For a long time, decoding has been treated as an implementation detail. Something you tweak with temperature and top_p until it “feels right.”
But as we move into the world of:
- coding agents,
- tool-calling LLMs,
- workflow orchestrators, and
- systems we actually depend on,
we need to treat decoding as a first-class design space:
- What information about uncertainty do we preserve?
- How do we constrain the model’s behavior without suffocating it?
- How do we let agents see and use the model’s uncertainty instead of hiding it?
Confident-Cluster Decoding is my attempt to answer those questions in a simple, practical way.
If this sparks ideas for you:
- Feel free to steal it, implement it, hack on it.
- If you’re running a lab or a company working on coding agents, I’d love to hear your thoughts.
- If you want to collaborate on the paper, benchmarks, or open-source library, my inbox is wide open.
This is just the beginning — and I think CCD is one of those small, composable ideas that will quietly show up in a lot of serious LLM systems over the next few years.
Thanks for reading. If you experiment with CCD, please share what you find — failures, weird cases, cool successes — they’re all gold for improving the idea.
Build CCD With Us
Ready to take CCD for a spin? Head over to the Confident-Cluster Decoding GitHub repo to follow the roadmap, open issues, or contribute experiments.
 Announcing FireGen: Turn Firebase RTDB into Your Universal Generative AI API
Announcing FireGen: Turn Firebase RTDB into Your Universal Generative AI API