![]()
![]()
WeChat Robot
WeChat robots are very common operational tools that not only bring activity to WeChat groups, but can also develop different gameplay for various communities.
What I wanted to make was a poetry robot. When someone in the group @ mentions the robot or triggers it with a search term, the robot queries a relevant poem from an existing poetry database and replies in text form in the group.
After having this goal, I began a long journey of tinkering.
The reason I call it tinkering is because this journey was full of obstacles.
First, WeChat officially does not have related APIs. Should I consider Enterprise WeChat? I found that Enterprise WeChat has group robots, but they only support sending messages, not receiving them. Still need to find WeChat personal account APIs.
Then I looked at various open source solutions based on the Web version of WeChat. The most recent updates were basically from a few years ago, and I often saw issues about being unable to log in to the Web version of WeChat. I tried my WeChat development account - couldn’t log in to Web WeChat. Gave up.
Next, I tried Mocha-L/WechatPCAPI based on the PC version of WeChat. Although usable, there were quite a few problems. For example, couldn’t get messages from users whose nicknames contained emoji, and every time code was modified, WeChat had to be manually restarted. I believe these are solvable, but the developer hasn’t fully open-sourced the core code, so there was no way to proceed. The project homepage says there’s a free version and a paid version. I only successfully ran the paid version, and after a dozen days, it prompted that the trial period had expired. This solution based on non-standard HOOK can only use specified versions of PC WeChat and requires a Windows runtime environment. Considering I needed a relatively stable API for long-term operation, could run on a Linux server, and relatively safe message sending and receiving, I had to continue looking for better solutions.
Having tinkered to this point, I had a basic understanding of various solutions: mainly Web page, Xposed technology, PC Hook, iPad protocol, emulator, and MAC protocol - six types of solutions. Comparing stability and security, iPad protocol and Mac protocol solutions are relatively good, with more commercial applications.
At this point, I found beclass’s blog post 《Developing WeChat Bot Management Platform Based on Nodejs+Wechaty》. I discovered the Wechaty project, which supports iPad protocol. Although a token fee is required, you can apply to participate in the open source incentive program to get a free or even long-term valid token.
Implementation
Basic Architecture
Since I had tried various personal account API solutions in the early stage, I had already separated the poetry search part as an independent service. This search service accepts a query string and returns a json string containing the results.
As for the WeChat-related part, everything was handed over to Wechaty, including receiving WeChat messages and sending WeChat messages after querying poem content.
Poetry Search Service
This part was implemented with PHP+MySQL. The poetry database was imported from a certain poetry blog database, and a crawler was used to scrape related WeChat official account article information (the robot can send official account article links).
The difficulty in this part is that the poems in the blog database do not distinguish between title, content, poem author and other fields. Regular expressions need to be used to match each field’s content. Although most poems have a fixed format and you can determine the position of titles and poem authors in the entire string through specific html tags, poems added to the database at different periods have subtle format differences.
Initially, I tried to use one regular expression to describe as many format types as possible and describe the positions of all fields within it. After struggling for a while, I gave up.
Due to unfamiliarity with the specific operating mechanism of regular expressions, in my eyes it was that alien language that looks understandable but produces errors when written. I needed a tool to show how regular expressions match target strings step by step, accelerating my regex debugging process.
On the Windows platform, I used RegexBuddy. I discovered a better web platform regex debugging tool regex101. It not only clearly marks matching results, but also shows the step-by-step matching process of regex, which is crucial for debugging.
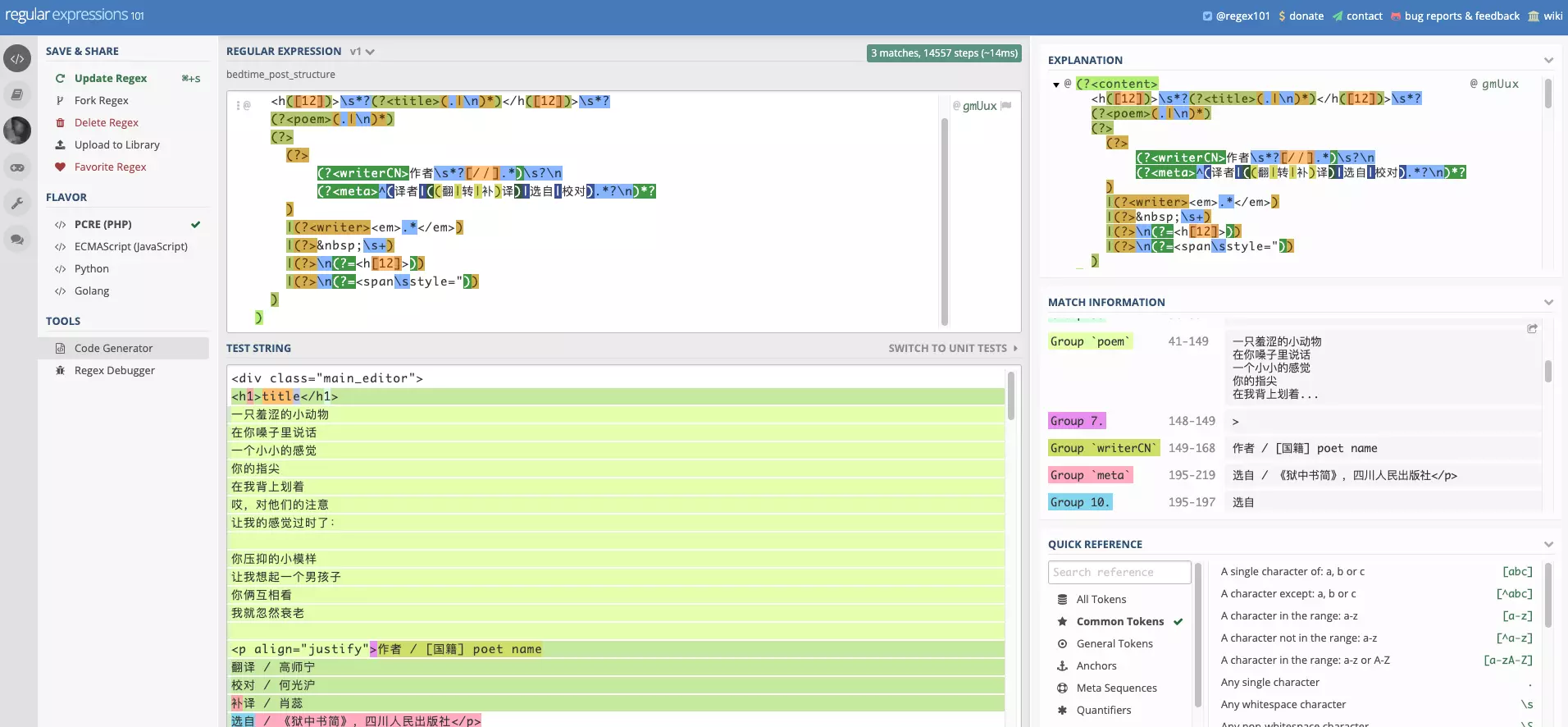
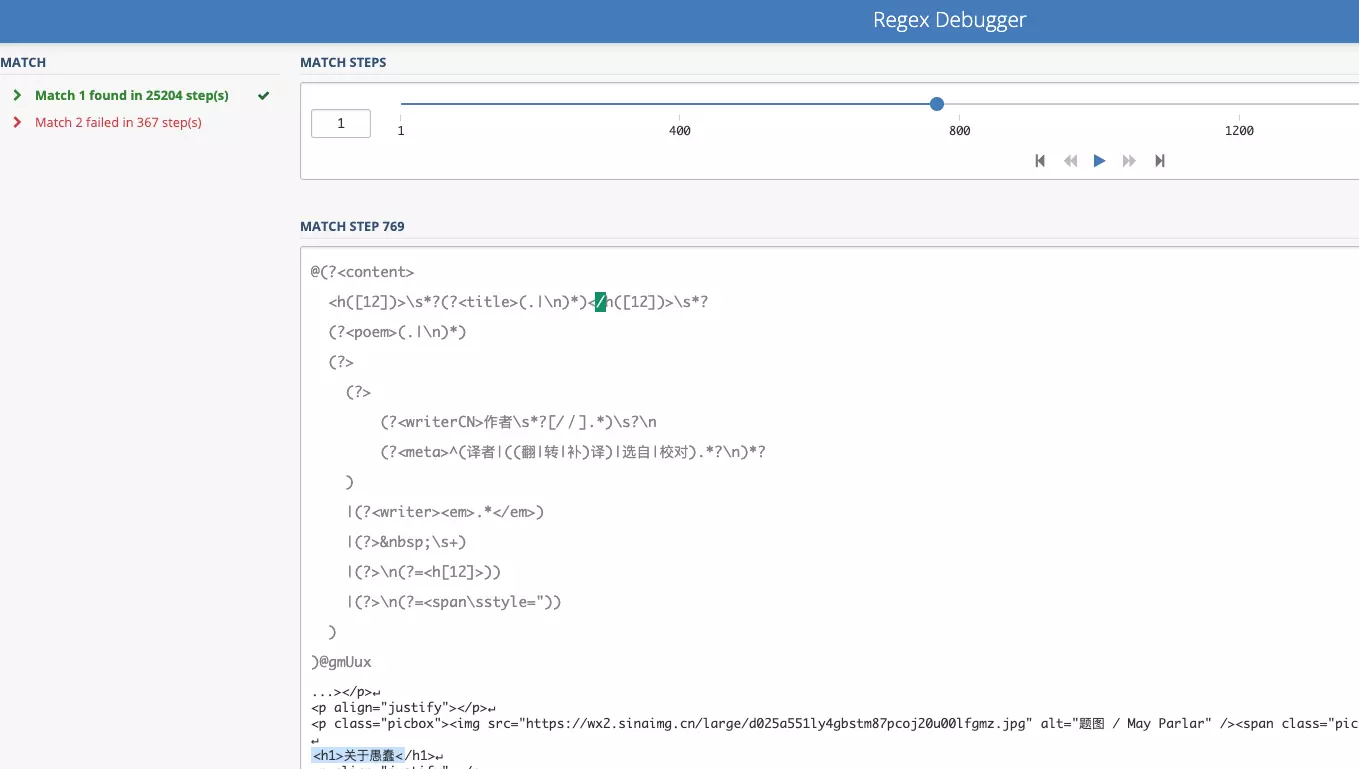
In addition to using regex to extract poem fields, keywords in various possible sentence patterns also need to be matched. Test cases are as follows:
public function testGetKeywordStartWithSearch() {
$this->assertEquals('', getKeyword('搜索'));
$this->assertEquals('诗', getKeyword('搜诗'));
$this->assertEquals('小黄诗', getKeyword('搜小黄诗'));
$this->assertEquals('一下', getKeyword('搜索 一下'));
$this->assertEquals('一下', getKeyword('搜 一下'));
$this->assertEquals('大人', getKeyword('搜大人'));
$this->assertEquals('你大爷', getKeyword('搜你大爷'));
$this->assertEquals('大人', getKeyword('搜一下大人的诗?'));
$this->assertEquals('李白', getKeyword('搜一搜李白的诗歌'));
$this->assertEquals('李白', getKeyword('搜一搜李白的诗.'));
$this->assertEquals('李白', getKeyword('搜一搜李白的诗。'));
$this->assertEquals('李白', getKeyword('搜一首李白的诗。'));
$this->assertEquals('李白', getKeyword('搜一首李白。'));
$this->assertEquals('李白', getKeyword('搜一搜李白的现代诗。'));
$this->assertEquals('唐', getKeyword('搜唐诗。'));
$this->assertEquals('宋', getKeyword('搜 宋词。'));
$this->assertEquals('搜索', getKeyword('搜索一下搜索'));
$this->assertEquals('dd索', getKeyword('搜索一下dd索'));
$this->assertEquals('搜索', getKeyword('搜搜索'));
$this->assertEquals('搜索', getKeyword('搜 搜索'));
$this->assertEquals('搜索', getKeyword('搜索 搜索'));
$this->assertEquals('你大姐', getKeyword('搜索:你大姐'));
$this->assertEquals('你大姐', getKeyword('搜索:你大姐'));
$this->assertEquals('text', getKeyword('search text'));
}
public function testGetKeywordStartWithOther() {
$this->assertEquals('', getKeyword('帮我找'));
$this->assertEquals('辛弃疾拍栏杆', getKeyword('我想要辛弃疾拍栏杆的诗'));
$this->assertEquals(['辛弃疾', '拍', '栏杆'], getKeyword('我想要辛弃疾拍栏杆的诗', true));
$this->assertEquals('一下', getKeyword('来一首 一下的诗'));
$this->assertEquals('杜牧', getKeyword('给我来一个杜牧的诗'));
$this->assertEquals('李商隐', getKeyword('给我来一个 李商隐的诗'));
$this->assertEquals('杜甫', getKeyword('给我一个杜甫的诗'));
$this->assertEquals('杜牧', getKeyword('告诉我一首杜牧的诗'));
$this->assertEquals('海子写德令哈', getKeyword('我想要那个海子写德令哈的诗'));
$this->assertEquals('海子写半截', getKeyword('我想要哪个海子写半截的诗'));
$this->assertEquals('写诗', getKeyword('帮我找跟写诗有关的诗'));
$this->assertEquals('写诗', getKeyword('帮我找一首写诗的诗'));
$this->assertEquals('李白', getKeyword('有没有李白的诗歌'));
$this->assertEquals('李白', getKeyword('有没有李白的古诗'));
$this->assertEquals('杜甫', getKeyword('来一首杜甫的诗'));
$this->assertEquals('海子', getKeyword('有没有海子的现代诗'));
$this->assertEquals(['李白的', '现代'], getKeyword('有没有李白的 现代 诗'));
$this->assertEquals('天空', getKeyword('来一个带天空的诗'));
$this->assertEquals('天空', getKeyword('来一个带有天空的诗'));
$this->assertEquals('天空', getKeyword('来一个含"天空"的诗'));
$this->assertEquals('天空', getKeyword('来一个包含天空的诗'));
$this->assertEquals('天空', getKeyword('来一个含有天空的诗'));
$this->assertEquals('莎士比亚', getKeyword('有没有莎士比亚的十四行诗'));
$this->assertEquals('天空', getKeyword('有没有跟天空相关的诗'));
$this->assertEquals('天空', getKeyword('有没有和天空有关的诗'));
$this->assertEquals('唐', getKeyword('来一首唐诗'));
$this->assertEquals('宋', getKeyword('给我来一个宋词'));
$this->assertEquals('宋', getKeyword('给我来个宋词'));
$this->assertEquals('天空', getKeyword('有没有跟天空相关的诗歌'));
$this->assertEquals('', getKeyword('一首没有人的诗'));
$this->assertEquals('', getKeyword('那个写火车的诗'));
$this->assertEquals('', getKeyword('帮我找'));
$this->assertEquals('', getKeyword('有没人'));
$this->assertEquals('', getKeyword('有没有人'));
$this->assertEquals('', getKeyword('有没有谁能告诉我'));
}
This part also took quite a bit of time. The final keyword extraction method is as follows:
/**
* @param string $str
* @param boolean $divide
* @return string[]|string
*/
function getKeyword($str, $divide = false) {
$str = trim(preg_replace('@[[:punct:]\n\r~| \s]+@u', ' ', $str));
$keyword = '';
$matches = [];
preg_match('@^(搜索??|search)(一下|一搜|一首|一个)??\s*?(?<keyword>.*)(的?((古|现代)?诗歌?|词))?$@Uu', $str, $matches);
if(isset($matches['keyword'])) {
$keyword = trim($matches['keyword']);
} else {
$matches = [];
preg_match('@^(有没有??|告诉我|帮我找|我想要|(给我来|给我|来)|搜索?)(一首|(一|那|哪)?个|一下)??((和|跟|带|包?含)有??)??\s*?(?<keyword>.*)((有关|相关)?的?((十四行|十六行|古|现代)?诗歌?|词))$@Uu', $str, $matches);
$keyword = isset($matches['keyword']) ? trim($matches['keyword']) : '';
}
// In some cases, word segmentation results may need to be returned
if($divide) {
return Jieba::cut($keyword);
}
return strstr($keyword, ' ')
? explode(' ', $keyword)
: $keyword;
}
The Chinese word segmentation part uses jieba-php. The efficiency is not very high and memory usage is relatively large, but acceptable.
Using Wechaty to Send and Receive Messages
In Wechaty, different Puppets correspond to different protocols. Wechaty also has SDKs in different languages, as well as demo template repositories, very friendly to developers, with high developer participation.
Thanks to beclass who has already open-sourced a successful case, I didn’t have to start from scratch, but made small code changes based on beclass/wxbot.
beclass’s article has already introduced the wxbot project. I won’t analyze wxbot’s code in detail below, just extract key parts.
First, you need to initialize a bot:
// create a Wechaty instance as bot
let bot = new Wechaty({
puppet: new PuppetPadplus({
token: puppet_padplus_token
}),
name: 'poem'
})
Since the token applied for is for the iPad protocol, PuppetPadplus is used here.
Then bind event handler functions to the bot, where the message event is triggered when a message is received.
bot.on('scan', (qrcode) => {
// show the qrcode
}).on('login', onLogin)
.on('message', onMessage(bot))
.on('friendship', onFriendShip)
.on('room-join', onRoomJoin)
.on('room-leave', onRoomLeave)
.on('error', error => {
logger.error('机器故障,error:' + error)
})
.on('logout', onLogout)
onMessage is written in server/robot/message
async function onMessage(msg) {
// Ignore messages from self
if (msg.self()) return
// Currently only handling text messages from group chats
if (msg.type() == Message.Type.Text) {
const room = msg.room()
const text = msg.text()
// Message from group chat
if (room) {
if (await msg.mentionSelf()) { // @ mentioned the bot
let self = await msg.to()
self = "@" + self.name()
let receivedText = text.replace(self, "").trim()
let content = await getPoemReply(receivedText, room.id)
// Return message and @ the sender
if(content.poem) {
let poem = "\n\n" + content.poem
room.say(poem, msg.from())
if(!content.data.wxPost) {
return;
}
const linkPayload = new UrlLink({
description : '点击查看读睡荐诗',
thumbnailUrl: content.data.wxPost.cover_src,
title : content.data.wxPost.title,
url : content.data.wxPost.link,
})
room.say(linkPayload)
}
return
} else { // Did not @ the bot
const receivedText = text.trim()
// Only process messages containing keywords
if(!isSearchString(receivedText)) {
return;
}
const content = await getPoemReply(receivedText, room.id)
if(content) room.say(content.poem)
return
}
}
return
}
}
function isSearchString(text) {
return /^搜/.test(text) || /的诗歌?$/.test(text)
}
/**
* @description Reply content
* @param {String} info Received message
* @return {Promise} Response content
*/
async function getPoemReply(word, chatRoomId) {
let url = POEMAPI_HOST + '/bot_search.php'
const pkg = {
method: 'get',
headers: {
'Content-Type': 'application/json'
},
data: {
keyword: word,
chatroom: chatRoomId
},
encoding: null,
timeout: 5000,
}
let { status, data } = await urllib.request(url, pkg)
if (status !== 200) return '不好意思,我出故障了.'
data = JSON.parse(data.toString())
return data
}
Launch
For running in production environment, it’s recommended to use PM2.
It’s also very simple to use. Add a configuration file pm2.config.js
module.exports = {
apps: [{
name: "wx-robot",
script: "./server/index.js",
env: {
NODE_ENV: "production",
}
}]
}
Then execute pm2 start pm2.config.js on the command line.
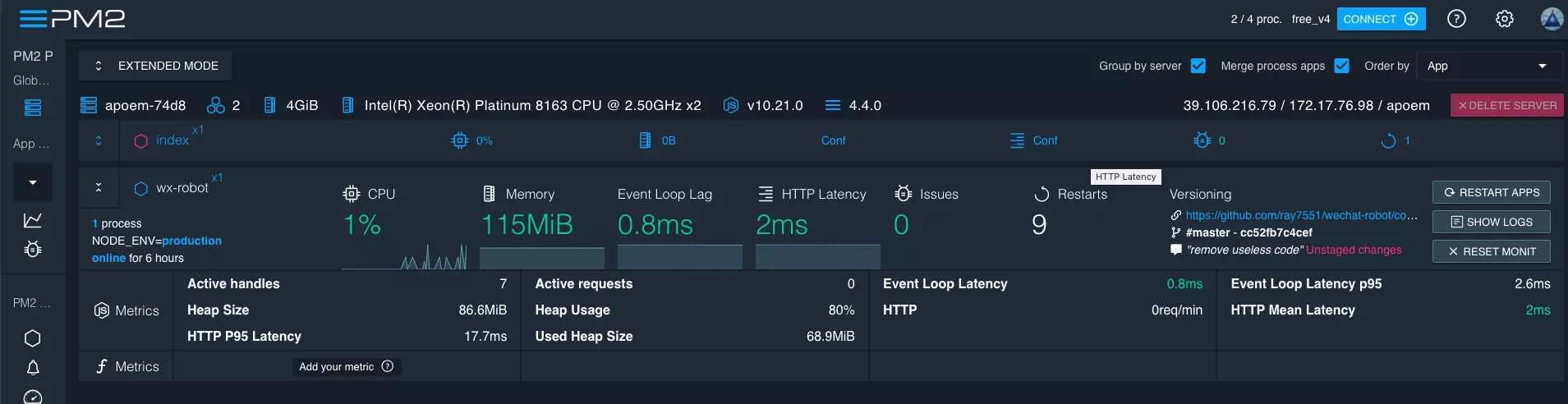
Combined with its monitoring panel service PM2+, you can not only control task running status in the browser, but also view real-time logs:
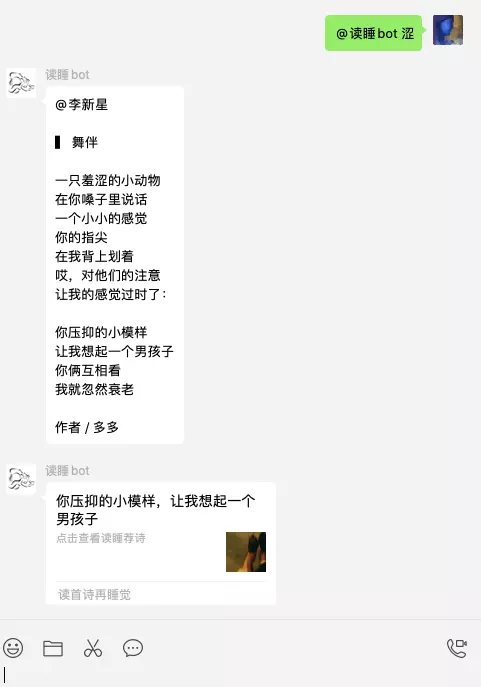
Goal achieved:
Conclusion (and Advertisement)
The part I think was most important during the development phase - matching keywords in various search sentence patterns - took a lot of time. I even considered using NL2SQL (Natural Language to SQL) technology. Actually, after going online, very few people used it. Most people still prefer to trigger the robot search with search+keyword. Although I was happy during the development process, it’s still quite sad that no one uses it.
Areas that can still be improved or expanded:
- Use ElasticSearch instead of MySQL for search, perform word segmentation on poem content (for poem content, getting word segmentation correct is difficult), to make search results more accurate.
- Set the bot’s function switches separately for different groups.
- Search results each time should be as different as possible.
- Famous line response mode: If a message is determined to be a famous line, the bot continues the next line.
- Flying flower order mode: Poem line relay.
- When patted, pat back.
Such a common requirement as WeChat bots should have a simple approach. After excluding various unreliable solutions, I chose Wechaty. Wechaty’s concise API can help developers quickly build a WeChat personal account bot. Developers who don’t have time to tinker don’t need to spend time trying other solutions.
One More Thing
During the writing of this article, I kept thinking, what kind of technical blog post is good? Describing various details is certainly useful to other developers. But software is constantly changing, and these useful details may soon become inapplicable, instead becoming information noise in developers’ search processes.
Redis developer Salvatore Sanfilippo said in this article
Sometimes I believe that software, while great, will never be huge like writing a book that will survive for centuries. Not because it is not as great per-se, but because as a side effect it is also useful… and will be replaced when something more useful is around.
In my view, good technical blog posts should not only have details, but also reflection on details and observation of the development process itself, trying to extract experiences that make the development process smoother. These experiences can even be extended to the handling of other daily affairs.
The internet produces and copies so many technical blog posts every day - how many can still inspire people after many years?
Author: ray7551
本文也有中文版本。
 微信计算器机器人(wechat robot calculator)
微信计算器机器人(wechat robot calculator)