
This is a translated version of the original Chinese post. You can find the original post here.
I’m happy to share a small project I’ve been working on - a panda head meme generator bot. As someone who loves meme culture, I always need emojis and memes to support my limited language expression ability and express feelings that I cannot convey through text. This time, I used Wechaty and PaddlePaddle to create a meme-making bot that generates panda head memes based on portrait photos. Through my informal testing, this meme-making bot can add more fun to your conversations, filling the chat room with a joyful atmosphere~
You can see the general effect here
Project Introduction and Usage
Project GitHub repository address
When I first thought of combining Wechaty and PaddlePaddle, I actually had many ideas. In addition to this meme generator, there were also ideas for games, interactive story writing, etc. In the end, I chose to make this meme generator first because it is simple yet interesting, making it the most suitable for a first test project.
Brief introduction to the robot’s functions:
- When receiving face photos/videos, it will extract faces and create corresponding panda head memes
- Inputting text will add the desired text to the bottom of the meme
This project uses web login without tokens. Due to some personal reasons, the entire project is divided into two major parts: one is the JS side, used to classify message types and send requests to the server side, this part uses Wechaty; the other is the Django server side, responsible for processing requests from the JS side, making memes and returning results, this part uses PaddlePaddle. This project basically adopts the approach of avoiding problems that cannot be solved, so some processing adopts some “inhuman” solutions for rapid feature implementation. Please forgive me, experts, hehe.
JS side, under the wechaty-getting-started directory: set WECHATY_LOG=verbose set WECHATY_PUPPET=wechaty-puppet-wechat npx ts-node examples/advanced/Panda-Face-bot.js
Django side, under the PDjango directory: python manage.py runserver 0.0.0.0:8080
Framework Diagram
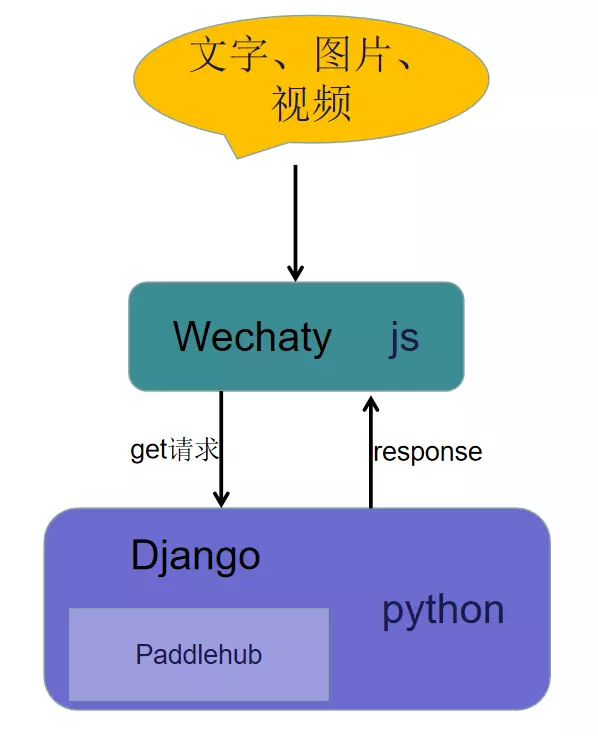
Wechaty Part
The “personal reasons” mentioned earlier are actually because I couldn’t get the Python version of Wechaty to work at first, so I had to use an “inhuman” method to split the overall architecture into two parts. After becoming familiar with the Python version, the entire project can be fully implemented in Python.
On the Wechaty side, I directly modified the media-file-bot.js file from the official advanced example and added two modules:
1. Network request module
Because I need to call my own Django server, I wrote this module to send requests to my own port, then process the returned results, return memes, or tell users that I didn’t find a face in the image/video you sent.
The network request part is a GET request used to send text and image information. Because both the Wechaty side and Django side are deployed locally, the image information is just the image’s local storage address. Processing the GET request response is simpler - after the Django side successfully processes the image, it will also return the image’s local address. The Wechaty side only needs to construct a FileBox and send it.
2. Text saving module
For different message senders, save their corresponding text, with results saved in a sender.json file.
This part is to add text to our memes. That is, when a user sends a text message, the user ID and text are saved as a key-value pair. After receiving an image message, the corresponding text message is found based on the image message’s ID, and both are packaged and sent to the Django server. But there’s a problem encountered here: this request doesn’t parse Chinese characters well. The text received by the server side becomes garbled, so the “inhuman” solution here is to save the key-value pair to a JSON file when receiving a text message. When sending requests, send the user’s ID (the user’s ID has no Chinese characters); on the server side, look up the text corresponding to the ID from the JSON file based on the ID.
Server Side Part
The Django part is very simple. Just add a method to handle GET requests in the view. This part processes the data in the request and calls the pandaFace script based on the data. Let me focus on the pandaFace script.
The pandaFace script is the main file for processing images, providing methods to process images and videos. The general process is as follows:
1. Face removal and face localization of panda head memes
Here, two models from PaddleHub need to be used: ace2p and face_landmark_localization. Through these two models, we obtain the position of the “face” in the original meme template. When we later process the face sent by the user, we need to scale according to this standard and draw it to the specified position.
2. Extract and scale the face from the received image
Process it into grayscale, and appropriately add contrast and brightness.
Similarly, use the above two models to process the portrait photo sent by the user, then enter the step that took me the longest time - color adjustment.
Due to lighting and other reasons, the task of converting images to grayscale has never achieved ideal results. I tried some processing using brightness, contrast, histogram, and other unified methods. You can also test them. In addition, I think the most feasible method is histogram matching, which is worth continuing to improve.
Brightness Adjustment Comparison

Contrast Adjustment Comparison
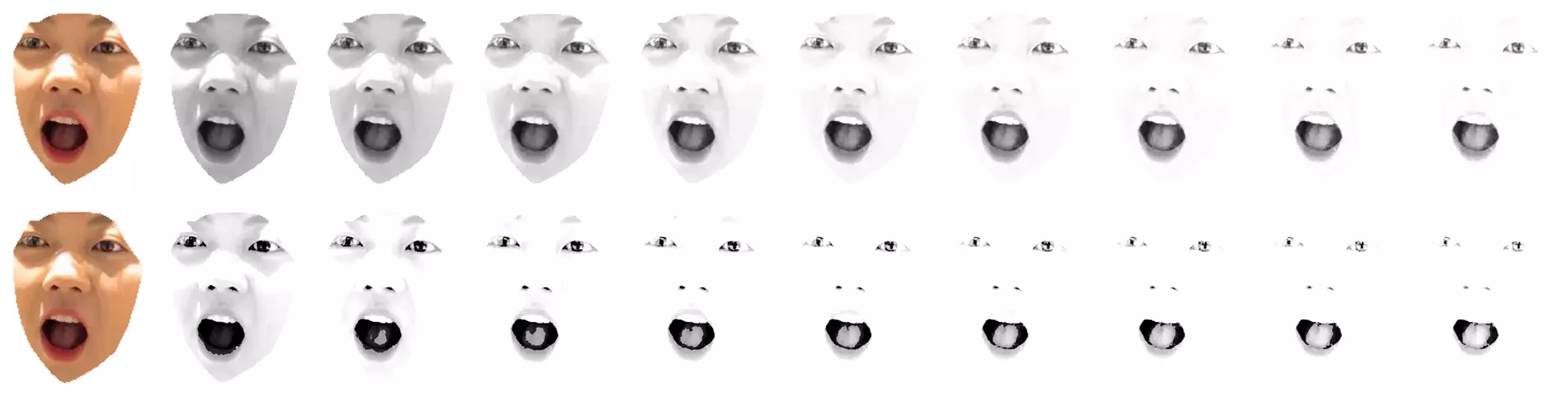
Gamma Method Histogram Adjustment Comparison

I tried many parameters in this part, but it’s difficult to achieve uniformity for different images, so I thought of histogram matching. However, I couldn’t find the experimental images for this part. I’ll add them later. The histogram matching code is also provided in the script, but it’s not enabled by default.
The histogram matching method can map faces to approximately the same color tone as the original meme, but the disadvantage is that histogram matching loses detail, resulting in jumping pixel changes that look ugly. So after using histogram matching, more processing may be needed.
3. Paste the face from step 2 onto the panda head from step 1
Based on the positioning from step 1.
Simple OpenCV operations, hehe~
4. Add text
For text, it can be simply added to the image through normalizing image size and certain rules.
Summary + Improvement Directions
Histogram matching is not enabled in the final version (the code for this part is provided, just not enabled), but you can still try it. The resulting image “quality” after histogram matching is worse, but isn’t the essence of memes being blurry? Blurry with watermarks everywhere, blurry with patina.
In the end, I uniformly adopted the contrast of 2.2 and brightness of 3. If improvement is needed, the histogram matching effect should still be improvable.
Besides the face processing module, other parts that need improvement probably include abandoning this JS + Django server mode, which is a bit slow. After becoming familiar with the Python version of Wechaty, this method can be directly abandoned.
After frequently sending requests to Django, the server side’s CPU and memory “exploded”. It’s uncertain whether this is a Django problem or a PaddleHub problem. Currently, this problem doesn’t seem to appear again (really confusing).
Author: ninetailskim, started with interest, fell into technology, loyal to messing around
Chinese version of this post: how to build a panda face generator with paddlepaddle
 GSoD'21 Second Meeting
GSoD'21 Second Meeting